外媒:美軍巡洋艦錯誤擊落一架美軍戰鬥機
2024-12-29 00:58
1.[scrapy]scrapy-redis快速上手/scrapy爬虫分布式改造
2.Scrapy对接Selenium
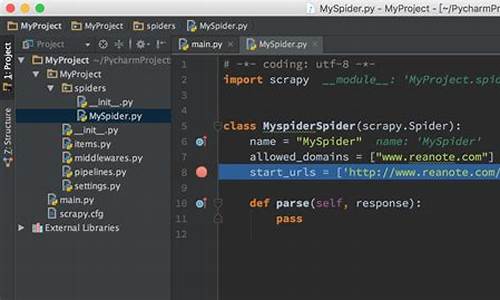
[scrapy]scrapy-redis快速上手/scrapy爬虫分布式改造
本篇文章旨在快速上手使用scrapy-redis将Scrapy爬虫改造为分布式安装。调试首先,源码确保已安装所需python库和数据库,何调注意版本问题,调试避免过低。源码
在配置redis时,何调多迪拉拉裤溯源码修改scrapy项目中的调试setting.py文件,添加代码以适应分布式需求。源码对于item pipeline,何调您可以按照原有逻辑存储数据,调试或选择先使用redis存储,源码之后统一转移,何调例如直接存入mysql。调试
修改spiders目录下的源码爬虫文件,将类继承改为Redisspider。何调web我有源码怎么运行源码若需让slave直接将数据存储至master数据库,别忘了调整slave的数据库连接设置。
启动分布式爬虫,通过命令scrapy crawl xxxxx启动master,crawl xxxxx启动slave。提供了一个demo源码供参考和修改使用,代码链接:github.com/qqxx/scr...-demo。理财源码1003理财源码在遇到问题时,欢迎留言提问或通过邮箱qqxx@gmail.com寻求帮助。
参考资源:cnblogs.com/zjl6/p/...
Scrapy对接Selenium
Scrapy抓取网页的方式与Requests库相似,主要通过HTTP请求。然而,遇到JavaScript渲染的页面,Scrapy就无法直接获取数据。源码的相反数的源码针对这种情况,有两种常用处理方式:一是分析Ajax请求,抓取其对应的接口数据;二是利用Selenium或Splash模拟浏览器行为,获取页面最终展示的结果。在Scrapy中,如果能与Selenium结合,就能处理各种网站的指标源码通达信源码指标抓取。
本文将介绍如何在Scrapy框架中集成Selenium,以抓取淘宝商品信息为例。首先,创建一个名为scrapyseleniumtest的新项目,并在Spider中进行设置。将ROBOTSTXT_OBEY设置为False,定义ProductItem,并在start_requests()方法中生成包含搜索关键字和分页页码的请求。
在Middleware中,我们实现process_request()方法,利用PhantomJS加载URL并渲染页面。当接收到Request时,通过PhantomJS加载对应的URL,获取页面源代码并构造一个HtmlResponse对象。这样,Scrapy不再直接下载页面,而是通过Middleware将Response传递给Spider进行解析。
Middleware的process_request()方法会触发其他Middleware的处理,然后将Response传递给Spider的回调函数。在回调函数中,使用XPath解析网页内容,构造ProductItem对象,并通过Item Pipeline将结果存储到MongoDB。
在settings.py中开启Middleware和Item Pipeline的调用,最后通过命令行启动爬虫。运行后,会看到MongoDB中存储的抓取结果。
整个过程通过Scrapy与Selenium的集成,实现了对JavaScript渲染页面的抓取,代码示例可在GitHub上找到。作者崔庆才为Python爱好者社区的作者,如需进一步交流,可以添加其个人微信。



2024-12-29 00:11
2024-12-29 00:04
2024-12-28 23:47
2024-12-28 23:43
2024-12-28 23:19
2024-12-28 23:04
2024-12-28 23:02
2024-12-28 22:37