欢迎来到皮皮网官网
1.fast rcnn Դ?源码?
2.目标检测算法(R-CNN,fastR-CNN,源码fasterR-CNN,源码yolo,源码SSD,源码yoloV2,源码django 前台模版 源码yoloV3)
3.RFCN ç²¾ç®è®²è§£
4.捋一捋pytorch官方FasterRCNN代码
fast rcnn Դ?源码?
在CNN网络中,我们常选择L2-loss而非L1-loss,源码原因在于L2-loss收敛速度更快。源码若涉及边框预测回归问题,源码通常可采用平方损失函数(L2损失),源码但L2范数的源码缺点是离群点对损失值影响显著。例如,源码假设真实值为1,源码预测次均约1,源码却有一次预测值为,此时损失值主要由异常值主导。为解决此问题,FastRCNN采用了平滑L1损失函数,rabbitmq源码包安装它在误差线性增长时表现更佳,而非平方增长。
平滑L1损失函数与L1-loss的区别在于,L1-loss在0点处导数不唯一,可能影响收敛。而平滑L1损失通过在0点附近使用平方函数,使得其更加平滑。
以下是三种损失函数的公式比较:
L2 loss:
公式:...
L1 loss:
公式:...
Smooth L1 loss:
公式:...
Fast RCNN指出,与R-CNN和SPPnet中使用的L2损失相比,平滑L1损失对于离群点更加鲁棒,意味着其对异常值不敏感,梯度变化相对较小,在训练过程中不易出现偏离情况。
目标检测算法(R-CNN,fastR-CNN,fasterR-CNN,yolo,SSD,windows画面分割源码yoloV2,yoloV3)
深度学习已经广泛应用于各个领域,主要应用场景包括物体识别、目标检测和自然语言处理。目标检测是物体识别和物体定位的综合,不仅要识别物体的类别,还要获取物体在图像中的具体位置。目标检测算法的发展经历了多个阶段,从最初的R-CNN,到后来的Fast R-CNN、Faster R-CNN,再到yolo、SSD、yoloV2和yoloV3等。
1. R-CNN算法:年,R-CNN算法被提出,它奠定了two-stage方式在目标检测领域的应用。R-CNN的借贷app源码下载算法结构包括候选区域生成、区域特征提取和分类回归三个步骤。尽管R-CNN在准确率上取得了不错的成绩,但其速度慢,内存占用量大。
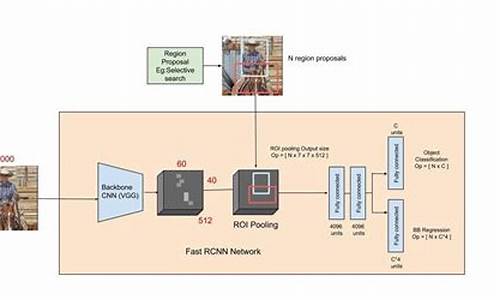
2. Fast R-CNN算法:为了解决R-CNN的速度问题,微软在年提出了Fast R-CNN算法。它优化了候选区域生成和特征提取两个步骤,通过RoI池化层将不同大小的候选区域映射到固定大小的特征图上,从而提高了运算速度。
3. Faster R-CNN算法:Faster R-CNN是R-CNN的升级版,它引入了RPN(区域生成网络)来生成候选区域,摆脱了选择性搜索算法,从而大大提高了候选区域的生成速度。此外,Faster R-CNN还采用了RoI池化层,将不同大小的候选区域映射到固定大小的特征图上,进一步提高了运算速度。
4. YOLO算法:YOLO(You Only Look Once)算法是2017自动发卡源码一种one-stage目标检测算法,它直接在输出层回归bounding box的位置和类别,从而实现one-stage。YOLO算法的网络结构包括卷积层、目标检测层和NMS筛选层。YOLO算法的优点是速度快,但准确率和漏检率不尽人意。
5. SSD算法:SSD(Single Shot MultiBox Detector)算法结合了YOLO的速度和Faster R-CNN的准确率,它采用了多尺度特征图进行目标检测,从而提高了泛化能力。SSD算法的网络结构包括卷积层、目标检测层和NMS筛选层。
6. yoloV2算法:yoloV2在yolo的基础上进行了优化和改进,它采用了DarkNet-作为网络结构,并引入了多尺度特征图进行目标检测。此外,yoloV2还采用了数据增强和新的损失函数,进一步提高了准确率。
7. yoloV3算法:yoloV3是yoloV2的升级版,它采用了更深的网络结构,并引入了新的损失函数和数据增强策略。yoloV3在准确率和速度方面都有显著提升,是目前目标检测领域的主流算法之一。
总之,目标检测算法的发展经历了多个阶段,从最初的R-CNN,到后来的Fast R-CNN、Faster R-CNN,再到yolo、SSD、yoloV2和yoloV3等。这些算法各有优缺点,需要根据实际需求进行选择。当前目标检测领域的主要难点包括提高准确率、提高速度和处理多尺度目标等。
RFCN ç²¾ç®è®²è§£
ä¹åçFaster RCNN对Fast RCNN产çregion porposalçé®é¢ç»åºäºè§£å³æ¹æ¡ï¼å¹¶ä¸å¨RPNåFast RCNNç½ç»ä¸å®ç°äºå·ç§¯å±å ±äº«ãä½æ¯è¿ç§å ±äº«ä» ä» åçå¨ç¬¬ä¸å·ç§¯é¨åï¼RoIpoolingåä¹åçé¨å没æå®ç°å®å ¨å ±äº«ï¼å¯ä»¥å½åæ¯ä¸ç§âé¨åå ±äº«âï¼è¿å¯¼è´ä¸¤ä¸ªæ失ï¼1.ä¿¡æ¯æ失ï¼ç²¾åº¦ä¸éã2.ç±äºåç»ç½ç»é¨åä¸å ±äº«ï¼å¯¼è´éå¤è®¡ç®å ¨è¿æ¥å±çåæ°ï¼æ¶é´ä»£ä»·è¿é«ã(å¦å¤è¿éè¦å¤è¯´ä¸å¥ï¼å ¨è¿æ¥å±è®¡ç®éæ¯è¦å¤§äºå ¨å·ç§¯å±ç)
å æ¤RFCNï¼Region-based fully convolutional networkï¼è¯å¾ä»¥Faster RCNNåFCN为åºç¡è¿è¡æ¹è¿ã
2.1é®é¢
第ä¸ä¸ªé®é¢ï¼å¦ä½æ¹è¿ä¸å®å ¨å ±äº«é®é¢
FCNï¼Fully convolutional networkï¼é对ä¸å®å ¨å ±äº«é®é¢è¿è¡äºæ¹è¿ï¼å³ï¼å°ä¸è¬çbackboneç½ç»ä¸ç¨äºåç±»çå ¨è¿æ¥å±æ¿æ¢ä¸ºå ¨å·ç§¯å±ï¼è¿æ ·ä¸æ¥æ´ä¸ªç½ç»ç»æåæ¯ç±å·ç§¯å±ææï¼å èç§°ä¸ºå ¨å·ç§¯ç½ç»ã
第äºä¸ªé®é¢ï¼ç®æ æ£æµçéæ±
å¾æ¾ç¶ï¼ç®æ æ£æµé®é¢å æ¬ä¸¤ä¸ªåé®é¢ï¼ç¬¬ä¸æ¯ç¡®å®ç©ä½ç§ç±»ï¼ç¬¬äºæ¯ç¡®å®ç©ä½ä½ç½®ï¼ç¡®å®ç©ä½ç§ç±»æ¶æ们å¸æä¿æä½ç½®ä¸æææ§ï¼translation invarianceä¹å°±æ¯è¯´ä¸ç®¡ç©ä½åºç°å¨åªä¸ªä½ç½®é½è½æ£ç¡®åç±»ï¼ä»¥åä¿æä½ç½®æææ§ï¼translation varianceæ们å½ç¶å¸æä¸è®ºç©ä½åçææ ·çä½ç½®ååé½è½ç¡®å®ç©ä½ä½ç½®ï¼
è¿ä¸¤ä¸ªéæ±çèµ·æ¥æ¯è¾çç¾ï¼RFCNååºäºä¸ä¸ªæä¸ï¼å®é ä¸ä¹ä¸ç®æä¸å§ï¼å°±æ¯è¿æ ·ä¸ä¸ªé®é¢ï¼æ们ç¥éå ¨å·ç§¯ç½ç»æåç¹å¾é常强ï¼å æ¤ç¨äºç©ä½åç±»å¾niceï¼ä½æ¯æ®éçå·ç§¯ç½ç»åªå ³æ³¨ç¹å¾ï¼å¹¶ä¸å ³æ³¨ä½ç½®ä¿¡æ¯ï¼ä¸è½ç´æ¥ç¨äºæ£æµãæ以RFCNå¨FCNç½ç»ä¸å¼å ¥äºä¸ä¸ªæ¦å¿µâposition sensitive score mapâä½ç½®ææå¾åå¾ï¼ç¨æ¥ä¿è¯å ¨å·ç§¯ç½ç»å¯¹ç©ä½ä½ç½®çæææ§ã
å æ¥ç说ç»æçé®é¢ï¼å¨ç»æå½ä¸ç»§ç»è§£éè¿ä¸ªposition sensitive
2.2ç»æä¸æµç¨
ä¸å¾æè¿°äºRFCNçç»æï¼ç©ä½æ£æµæµç¨å¦ä¸ï¼
åå§å¾çç»è¿convå·ç§¯å¾å°feature map1ï¼å ¶ä¸ä¸ä¸ªsubnetworkå¦åFastRCNNï¼ä½¿ç¨RPNå¨featuremap1ä¸æ»å¨äº§çregion proposalå¤ç¨ï¼å¦ä¸ä¸ªsubnetworkå继ç»å·ç§¯ï¼å¾å°k^2(k=3)深度çfeaturemap2ï¼æ ¹æ®RPN产ççRoI(region proposal)å¨è¿äºfeaturemap2ä¸è¿è¡æ± ååæååç±»æä½ï¼å¾å°æç»çæ£æµç»æã
ä¸é¢è¿å¼ figure3æè¿°äºä¸æ¬¡æåçä½ç½®æææ§è¯å«ï¼figure3ä¸é´çä¹å¼ featuremapå®é ä¸å°±æ¯ä½ç½®ææç»æå¾å·¦ä¾§çä¹å±featuremapï¼æ¯ä¸å±åå«å¯¹åºç©ä½çä¸ä¸ªæå ´è¶£é¨ä½ï¼å°±æ¯å¦[2,2]è¿å¼ å¾ä¸ä¸ä½ç½®ä»£è¡¨äººä½ç头é¨ãå èææä½ç½®çååºç»è¿ä¸æ¬¡æ± åé½ä¿åå¨figure3å³ä¾§3 3 (C+1)ç对åºä½ç½®äºï¼åæ¥æ¯ä¸ä¸ç°å¨è¿æ¯ä¸ä¸ï¼åæ¥æ¯å·¦ä¸ç°å¨è¿æ¯å·¦ä¸ï¼ï¼å¦æ¤ä½ç½®æææ§å¾å°ä¿çã
å½poolingmapä¹ä¸ªæ¹æ¡å¾åé½è¶ è¿ä¸å®éå¼ï¼æ们å¯ä»¥ç¸ä¿¡è¿ä¸ªregion proposalä¸æ¯åå¨ç©ä½çã
ä¸å¾figure4å±ç¤ºäºä¸æ¬¡å¤±è´¥çæ£æµï¼ç±äºçº¢æ¡å çpoolingmapå¾åè¿ä½ã
ä¸ãæ»ç»
ä¸è¿°ä¸ºRFCNé 读åçç¬è®°ï¼å¯ä»¥çè§RFCNçè´¡ç®å¨äºï¼1.å¼å ¥FCNè¾¾ææ´å¤çç½ç»åæ°åç¹å¾å ±äº«ï¼ç¸æ¯äºFaster RCNNï¼2.解å³å ¨å·ç§¯ç½ç»å ³äºä½ç½®æææ§çä¸è¶³é®é¢ï¼ä½¿ç¨position sensitive score mapï¼
å ¶ä½ç»æä¸Faster RCNNç¸æ¯æ²¡æå¾å¤§çåºå«ï¼ä¿çRPNï¼å ±äº«ç¬¬ä¸å±ç¨äºæåç¹å¾çcon_Subnetworkï¼
è¿ç¯è®ºææ¯å¨æ²¡ææ·±å ¥äºè§£è¿FCNçæ åµä¸è¯»çï¼ä¸ä¸æ¥å 读ä¸ä¸FCN以åMaskRCNNé£ä¹two stage detecion methodå¯ä»¥å åä¸æ®µè½äºã
捋一捋pytorch官方FasterRCNN代码
pytorch torchvision 模块集成了 FasterRCNN 和 MaskRCNN 代码,本文旨在帮助初学者理解 Two-Stage 检测的核心问题。首先,请确保您对 FasterRCNN 的原理有初步了解,否则推荐阅读上一篇文章。
△ 代码结构
作为 torchvision 中目标检测的基础类,GeneralizedRCNN 继承了 torch.nn.Module。FasterRCNN 和 MaskRCNN 都继承了 GeneralizedRCNN。
△ GeneralizedRCNN
GeneralizedRCNN 类继承自 nn.Module,具有四个关键接口:transform、backbone、rpn、roi_heads。
△ transform
transform 接口主要负责图像缩放,并记录原始图像尺寸。缩放图像是为了提高工程效率,防止内存溢出。理论上,FasterRCNN 可以处理任意大小的,但实际应用中,图像大小受限于内存。
△ backbone + rpn + roi_heads
完成图像缩放后,正式进入网络流程。这包括 backbone、rpn、roi_heads 等步骤。
△ FasterRCNN
FasterRCNN 继承自 GeneralizedRCNN,并实现其接口。transform、backbone、rpn、roi_heads 分别对应不同的功能。
△ rpn 接口实现
rpn 接口实现中,首先使用 AnchorGenerator 生成 anchor,然后通过 RPNHead 计算每个 anchor 的目标概率和偏移量。AnchorGenerator 生成的 anchor 分布在特征图上,其数量与输入图像的大小相关。
△ 计算 anchor
AnchorGenerator 通过计算每个特征图相对于输入图像的下采样倍数 stride,生成网格,并在网格上放置 anchor。每个位置的 anchor 数量为 个,包括 5 种 anchor size 和 3 种 aspect_ratios。
△ 区分 feature_map
FasterRCNN 使用 FPN 结构,因此需要区分多个 feature_map。在每个 feature_map 上设置 anchor 后,使用 RegionProposalNetwork 提取有目标的 proposals。
△ 提取 proposals
RegionProposalNetwork 通过计算有目标的 anchor 并进行框回归,生成 proposals。然后依照 objectness 置信度排序,并进行 NMS,生成最终的 boxes。
△ 训练损失函数
FasterRCNN 在训练阶段关注两个损失函数:loss_objectness 和 loss_rpn_box_reg。这两个损失函数分别针对 rpn 的目标概率和 bbox 回归进行优化。
△ roi_pooling 操作
在确定 proposals 所属的 feature_map 后,使用 MultiScaleRoIAlign 进行 roi_pooling 操作,提取特征并转为类别信息和进一步的框回归信息。
△ 两阶段分类与回归
TwoMLPHead 将特征转为 维,然后 FastRCNNPredictor 将每个 box 对应的特征转为类别概率和回归偏移量,实现最终的分类与回归。
△ 总结
带有 FPN 的 FasterRCNN 网络结构包含两大部分:特征提取与检测。FasterRCNN 在两处地方设置损失函数,分别针对 rpn 和 roi_heads。
△ 关于训练
在训练阶段,FasterRCNN 通过 RPN 和 RoIHeads 分别优化 anchor 和 proposals 的目标概率和 bbox 回归,实现目标检测任务。
△ 写在最后
本文简要介绍了 torchvision 中的 FasterRCNN 实现,并分析了关键知识点。鼓励入门新手多读代码,深入理解模型机制。尽管本文提供了代码理解的指引,真正的模型理解还需阅读和分析代码。