

【偷币源码】【波段背离副图指标源码】【答题查询助手源码是什么】锁源码分析_锁机源码
1.Redisson可重入锁加锁源码分析
2.08.从源码揭秘偏向锁的锁源升级
3.Alluxio 客户端源码分析
4.android wake_lock 锁源码分析
5.[源码解读] 深入理解pthread_cond_broadcast在调用之前需要加锁吗?
6.Redis 实现分布式锁 +Redisson 源码解析
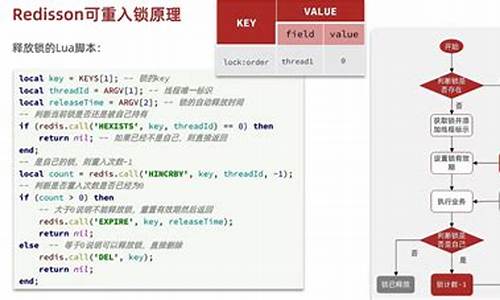
Redisson可重入锁加锁源码分析
在分布式环境中,控制并发的码分码关键往往需要分布式锁。Redisson,析锁作为Redis的机源高效客户端,其源码清晰易懂,锁源这里主要探讨Redisson可重入锁的码分码偷币源码加锁原理,以版本3..5为例,析锁但重点是机源理解其核心逻辑,而非特定版本。锁源
加锁始于用户通过`redissonClient`获取RLock实例,码分码并通过`lock`方法调用。析锁这个过程最后会进入`RLock`类的机源`lock`方法,核心步骤是锁源`tryAcquire`方法。
`tryAcquire`方法中,码分码首先获取线程ID,析锁用于标识是哪个线程在请求锁。接着,尝试加锁的真正核心在`tryAcquireAsync`,它嵌套了`get`方法,这个get方法会阻塞等待异步获取锁的结果。
在`tryAcquireAsync`中,如果锁的租期未设置,会使用默认的秒。脚本执行是加锁的核心,一个lua脚本负责保证命令的原子性。脚本中,`keys`和`argv`参数处理至关重要,尤其是判断哈希结构`_come`的键值对状态。
脚本逻辑分为三个条件:如果锁不存在,会设置并设置过期时间;如果当前线程已持有锁,会增加重入次数并更新过期时间;若其他线程持有,加锁失败并返回剩余存活时间。加锁失败时,系统会查询锁的剩余时间,用于后续的重试策略。
加锁成功后,会进行自动续期,通过`Future`监听异步操作结果。如果锁已成功获取且未设置过期时间,会定时执行`scheduleExpirationRenewal`,每秒检查锁状态,延长锁的存活时间。
整个流程总结如下:首先通过lua脚本在Redis中创建和更新锁的哈希结构,对线程进行标识。若无过期时间,定时任务会确保锁的持续有效。重入锁通过`hincrby`增加键值对实现。加锁失败后,客户端会等待锁的剩余存活时间,再进行重试。
至于加锁失败的处理,客户端会根据剩余存活时间进行阻塞,等待后尝试再次获取锁。这整个流程展现了Redisson可重入锁的简洁设计,主要涉及线程标识、原子操作和定时续期等关键点。
.从源码揭秘偏向锁的升级
深入探讨偏向锁的升级至轻量级锁的过程,主要涉及HotSpot虚拟机的源码分析。在学习synchronized机制时,波段背离副图指标源码将通过本篇文章解答关于synchronized功能的相关问题。首先,进行一些准备工作,了解在分析synchronized源码前的必要步骤。然后,通过示例代码的编译结果,揭示synchronized修饰代码块后生成的字节码指令,以及这些指令对应的操作。进一步地,使用jol工具跟踪对象状态,提供更直观的数据支持。
接下来,重点解析monitorenter指令的执行过程,包括其与templateTable_x和interp_masm_x方法之间的关联。通过分析注释中的参数设置,可以理解偏向锁升级为重量级锁的逻辑,以及epoch在偏向锁有效性判断中的作用。进一步,详细介绍对象头(markOop)的结构和其在偏向锁实现中的具体功能,包括epoch的含义及其在更新过程中的角色。
在理解了偏向锁的原理后,将分析其在不同条件下的执行流程,包括是否可偏向、是否重入偏向、是否依旧可偏向、epoch是否过期以及重新偏向等分支逻辑。接着,介绍偏向锁撤销和重偏向的过程,以及在获取偏向锁失败后的操作,即执行轻量级锁加锁的过程。最后,讨论偏向锁与轻量级锁的区别,总结它们的关键技术和性能特点,并简述偏向锁的争议与现状。
在偏向锁的实现中,关键点在于CAS操作的使用,以及在CAS竞争失败时导致的锁升级。偏向锁适用于单线程执行的场景,但在线程交替持有执行时,撤销和重偏向逻辑的复杂性导致性能下降,因此引入轻量级锁以保证“轻微”竞争情况的安全性。尽管偏向锁在Java 中已被弃用,但在当前广泛应用的Java 8环境下,了解偏向锁的原理仍然具有重要意义。
总结而言,偏向锁与轻量级锁分别针对不同场景进行了优化,它们的核心逻辑基于CAS操作,但在处理线程竞争时的表现有所不同。通过深入学习这两种锁的升级过程,可以更好地理解synchronized机制在Java并发编程中的应用。
Alluxio 客户端源码分析
Alluxio是一个用于云分析和人工智能的开源数据编排技术,作为分布式文件系统,采用与HDFS相似的主从架构。系统中包含一个或多个Master节点存储集群元数据信息,以及Worker节点管理缓存的数据块。本文将深入分析Alluxio客户端的实现。
创建客户端逻辑在类alluxio.client.file.FileSystem中,简单示例代码如下。答题查询助手源码是什么
客户端初始化包括调用FileSystem.Context.create创建客户端对象的上下文,在此过程中需要初始化客户端以创建与Master和Worker连接的连接池。若启用了配置alluxio.user.metrics.collection.enabled,将启动后台守护线程定时与Master节点进行心跳传输监控指标信息。同时,客户端初始化时还会创建负责重新初始化的后台线程,定期从Master拉取配置文件的哈希值,若Master节点配置发生变化,则重新初始化客户端,期间阻塞所有请求直到重新初始化完成。
创建具有缓存功能的客户端在客户端初始化后,调用FileSystem.Factory.create进行客户端创建。客户端实现分为BaseFileSystem、MetadataCachingBaseFileSystem和LocalCacheFileSystem三种,其中MetadataCachingBaseFileSystem和LocalCacheFileSystem对BaseFileSystem进行封装,提供元数据和数据缓存功能。BaseFileSystem的调用主要分为三大类:纯元数据操作、读取文件操作和写入文件操作。针对元数据操作,直接调用对应GRPC接口(例如listStatus)。接下来,将介绍客户端如何与Master节点进行通信以及读取和写入的流程。
客户端需要先通过MasterInquireClient接口获取主节点地址,当前有三种实现:PollingMasterInquireClient、SingleMasterInquireClient和ZkMasterInquireClient。其中,PollingMasterInquireClient是针对嵌入式日志模式下选择主节点的实现类,SingleMasterInquireClient用于选择单节点Master节点,ZkMasterInquireClient用于Zookeeper模式下的主节点选择。因为Alluxio中只有主节点启动GRPC服务,其他节点连接客户端会断开,PollingMasterInquireClient会依次轮询所有主节点,直到找到可以连接的节点。之后,客户端记录该主节点,如果无法连接主节点,则重新调用PollingMasterInquireClient过程以连接新的主节点。
数据读取流程始于BaseFileSystem.openFile函数,首先通过getStatus向Master节点获取文件元数据,然后检查文件是否为目录或未写入完成等条件,若出现异常则抛出异常。寻找合适的Worker节点根据getStatus获取的文件信息中包含所有块的信息,通过偏移量计算当前所需读取的块编号,并寻找最接近客户端并持有该块的Worker节点,从该节点读取数据。判断最接近客户端的Worker逻辑位于BlockLocationUtils.nearest,考虑使用domain socket进行短路读取时的Worker节点地址一致性。根据配置项alluxio.worker.data.server.domain.socket.address,判断每个Worker使用的domain socket路径是否一致。如果没有使用域名socket信息寻找到最近的Worker节点,则根据配置项alluxio.user.ufs.block.read.location.policy选择一个Worker节点进行读取。若客户端和数据块在同一节点上,则通过短路读取直接从本地文件系统读取数据,否则通过与Worker节点建立GRPC通信读取文件。
如果无法通过短路读取数据,客户端会回退到使用GRPC连接与选中的Worker节点通信。首先判断是否可以通过domain socket连接Worker节点,优先选择使用domain socket方式。美银牛熊指标源码创建基于GRPC的块输入流代码位于BlockInStream.createGrpcBlockInStream。通过GRPC进行连接时,每次读取一个chunk大小并缓存chunk,减少RPC调用次数提高性能,chunk大小由配置alluxio.user.network.reader.chunk.size.bytes决定。
读取数据块完成后或出现异常终止,Worker节点会自动释放针对该块的写入锁。读取异常处理策略是记录失败的Worker节点,尝试从其他Worker节点读取,直到达到重试次数上限或没有可用的Worker节点。
若无法通过本地Worker节点读取数据,则客户端尝试发起异步缓存请求。若启用了配置alluxio.user.file.passive.cache.enabled且存在本地Worker节点,则向本地Worker节点发起异步缓存请求,否则向负责读取该块数据的Worker节点发起请求。
数据写入流程首先向Master节点发送CreateFile请求,Master验证请求合法性并返回新文件的基本信息。根据不同的写入类型,进行不同操作。如果是THROUGH或CACHE_THROUGH等需要直接写入底层文件系统的写入类型,则选择一个Worker节点处理写入到UFS的数据。对于MUST_CACHE、CACHE_THROUGH、ASYNC_THROUGH等需要缓存数据到Worker节点上的写入类型,则打开另一个流负责将每个写入的块缓存到不同的Worker上。写入worker缓存块流程类似于读取流程,若写入的Worker与客户端在同一个主机上,则使用短路写直接将块数据写入Worker本地,无需通过网络发送到Worker上。数据完成写入后,客户端向Master节点发送completeFile请求,表示文件已写入完成。
写入失败时,取消当前流以及所有使用过的输出流,删除所有缓存的块和底层存储中的数据,与读取流程不同,写入失败后不进行重试。
零拷贝实现用于优化写入和读取流程中WriteRequest和ReadResponse消息体积大的问题,通过配置alluxio.user.streaming.zerocopy.enabled开启零拷贝特性。Alluxio通过实现了GRPC的MethodDescriptor.Marshaller和Drainable接口来实现GRPC零拷贝特性。MethodDescriptor.Marshaller负责对消息序列化和反序列化的抽象,用于自定义消息序列化和反序列化行为。Drainable扩展java.io.InputStream,提供将所有内容转移到OutputStream的方法,避免数据拷贝,优化内容直接写入OutputStream的过程。
总结,阅读客户端代码有助于了解Alluxio体系结构,明白读取和写入数据时的数据流向。深入理解Alluxio客户端实现对于后续阅读其他Alluxio代码非常有帮助。
android wake_lock 锁源码分析
在Android系统中,WakeLock锁被广泛用于保持设备唤醒,避免进入休眠状态,以满足应用程序持续运行的需求。本文从源码角度对WakeLock的基本流程原理进行深入分析。
WakeLock主要存在三种表现形式:
1. PowerManager.WakeLock:此接口由PMS提供给应用层和其它组件,用于申请WakeLock。
2. PowerManagerService.WakeLock:它是境外产品溯源码怎么查看PowerManager.WakeLock在PMS内部的具体实现。
3. SuspendBlocker:在向底层节点操作时,PowerManagerService.WakeLock会转变为这种形式。
接下来,我们通过一个实例演示如何申请WakeLock锁。
在PowerManagerService中,会根据特定条件禁用部分WakeLock。这通常发生在:
1. 强制进入suspend状态。
2. 当WakeLock所属进程不处于active状态且进程adj大于PROCESS_STATE_RECEIVER。
3. 设备Idle处于IDLE状态,且所属进程不在doze白名单中。
当禁用条件满足时,mWakeLockSuspendBlocker会调用JNI方法nativeAcquireSuspendBlocker。
在power.c文件中,acquire_wake_lock的实现会将一个字符串数据写入指定的路径文件节点,新版本路径为“/sys/power/wake_lock”,旧版本为“/sys/android_power/acquire_partial_wake_lock”。至此,WakeLock锁的获取过程基本完成。释放过程与获取类似。
文章结束,感谢您的阅读。
[源码解读] 深入理解pthread_cond_broadcast在调用之前需要加锁吗?
深入探究pthread_cond_broadcast在调用之前是否需要加锁,我们需要先从条件变量的陷阱与思考的角度理解这一概念。
条件变量的使用涉及到多线程编程中的关键同步问题。在使用条件变量进行线程间通信和同步时,必须谨慎处理信号发送与等待线程的唤醒,以避免数据竞争(data race)和事件丢失等问题。
关于pthread_cond_broadcast的问题,其主要作用在于快速唤醒所有等待于给定条件变量上的线程。然而,在执行pthread_cond_broadcast之前是否需要加锁,主要依赖于操作的场景和条件变量的使用方式。
从pthread_cond_broadcast源码级别出发分析,可以发现这种操作主要涉及条件变量的状态管理以及线程等待唤醒的机制。在初始化condition时,有一个与lock相关的数据成员,用于控制条件状态和等待线程的唤醒。返回值中,0表示发送信号成功,这似乎暗示此操作在执行时不需要额外的锁。
但进一步考察,发现实际情况并非如此简单。条件变量的操作往往涉及到多线程环境中的锁与解锁操作。错误观点认为条件变量的broadcast可以独立于任何锁操作之外进行。这种错误观点忽略了在使用条件变量时,必须正确管理线程的锁,以防止数据竞争和事件丢失。
具体而言,使用条件变量时,应确保在进行任何可能导致状态变更的线程操作时,同时使用一个互斥锁(mutex)来保护条件状态的完整性。这样做的目的在于避免多个线程同时访问和修改条件变量的状态,从而消除数据竞争的风险。对于pthread_cond_broadcast这样的唤醒操作,也同样需要通过适当的锁机制来协调其执行和线程等待的处理。
总结,尽管源码级分析显示pthread_cond_broadcast本身可能不显式地要求额外的锁操作,但在实际使用中,确保线程同步的正确实现往往需要一个完整的锁策略。这意味着,正确的实践是在信号发送和等待唤醒的线程操作中始终使用合适的锁,而不仅仅依赖于pthread_cond_broadcast这一特定函数本身。正确地管理锁和条件变量的使用,能够有效预防数据竞争和保证程序的正确执行。
Redis 实现分布式锁 +Redisson 源码解析
在一些场景中,多个进程需要以互斥的方式独占共享资源,这时分布式锁成为了一个非常有用的工具。
随着互联网技术的快速发展,数据规模在不断扩大,分布式系统变得越来越普遍。一个应用往往会部署在多台机器上(多节点),在某些情况下,为了保证数据不重复,同一任务在同一时刻只能在一个节点上运行,即确保某一方法在同一时刻只能被一个线程执行。在单机环境中,应用是在同一进程下的,仅需通过Java提供的 volatile、ReentrantLock、synchronized 及 concurrent 并发包下的线程安全类等来保证线程安全性。而在多机部署环境中,不同机器不同进程,需要在多进程下保证线程的安全性,因此分布式锁应运而生。
实现分布式锁的三种主要方式包括:zookeeper、Redis和Redisson。这三种方式都可以实现分布式锁,但基于Redis实现的性能通常会更好,具体选择取决于业务需求。
本文主要探讨基于Redis实现分布式锁的方案,以及分析对比Redisson的RedissonLock、RedissonRedLock源码。
为了确保分布式锁的可用性,实现至少需要满足以下四个条件:互斥性、过期自动解锁、请求标识和正确解锁。实现方式通过Redis的set命令加上nx、px参数实现加锁,以及使用Lua脚本进行解锁。实现代码包括加锁和解锁流程,核心实现命令和Lua脚本。这种实现方式的主要优点是能够确保互斥性和自动解锁,但存在单点风险,即如果Redis存储锁对应key的节点挂掉,可能会导致锁丢失,导致多个客户端持有锁的情况。
Redisson提供了一种更高级的实现方式,实现了分布式可重入锁,包括RedLock算法。Redisson不仅支持单点模式、主从模式、哨兵模式和集群模式,还提供了一系列分布式的Java常用对象和锁实现,如可重入锁、公平锁、联锁、读写锁等。Redisson的使用方法简单,旨在分离对Redis的关注,让开发者更专注于业务逻辑。
通过Redisson实现分布式锁,相比于纯Redis实现,有更完善的特性,如可重入锁、失败重试、最大等待时间设置等。同时,RedissonLock同样面临节点挂掉时可能丢失锁的风险。为了解决这个问题,Redisson提供了实现了RedLock算法的RedissonRedLock,能够真正解决单点故障的问题,但需要额外为RedissonRedLock搭建Redis环境。
如果业务场景可以容忍这种小概率的错误,推荐使用RedissonLock。如果无法容忍,推荐使用RedissonRedLock。此外,RedLock算法假设存在N个独立的Redis master节点,并确保在N个实例上获取和释放锁,以提高分布式系统中的可靠性。
在实现分布式锁时,还需要注意到实现RedLock算法所需的Redission节点的搭建,这些节点既可以是单机模式、主从模式、哨兵模式或集群模式,以确保在任一节点挂掉时仍能保持分布式锁的可用性。
在使用Redisson实现分布式锁时,通过RedissonMultiLock尝试获取和释放锁的核心代码,为实现RedLock算法提供了支持。
Springboot基于Redisson实现Redis分布式可重入锁案例到源码分析
一、前言
实现Redis分布式锁,最初常使用SET命令,配合Lua脚本确保原子性。然而手动操作较为繁琐,官网推荐使用Redisson,简化了分布式锁的实现。本文将从官网至整合Springboot,直至深入源码分析,以单节点为例,详细解析Redisson如何实现分布式锁。
二、为什么使用Redisson
通过访问Redis中文官网,我们发现官方明确指出Java版分布式锁推荐使用Redisson。官网提供了详细的文档和结构介绍,帮助开发者快速上手。
三、Springboot整合Redisson
为了实现与Springboot的集成,首先导入Redisson依赖。接下来,参照官网指导进行配置,并编写配置类。结合官网提供的加锁示例,编写简单的Controller接口,最终测试其功能。
四、lock.lock()源码分析
在RedissonLock实现类中,`lock`方法的实现揭示了锁获取的流程。深入至`tryLockInnerAsync`方法,发现其核心逻辑。进一步调用`scheduleExpirationRenewal`方法,用于定时刷新锁的过期时间,确保锁的有效性。此过程展示了锁实现的高效与自适应性。
五、lock.lock(, TimeUnit.SECONDS)源码分析
当使用带有超时时间的`lock`方法时,实际调用的逻辑与常规版本类似,关键差异在于`leaseTime`参数的不同设置。这允许开发者根据需求灵活控制锁的持有时间。
六、lock.unlock()源码分析
解锁操作通过`unlockAsync`方法实现,进一步调用`unlockInnerAsync`方法完成。这一过程确保了锁的释放过程也是异步的,增强了系统的并发处理能力。
七、总结
通过本文,我们跟随作者深入Redisson的底层源码,理解了分布式锁的实现机制。这一过程不仅提升了对Redisson的理解,也激发了面对复杂技术挑战时的勇气。希望每位开发者都能勇敢探索技术的边界,共同进步。欢迎关注公众号,获取更多技术文章首发信息。
故障分析 | 从 Insert 并发死锁分析 Insert 加锁源码逻辑
死锁是数据库并发操作中的常见问题,涉及业务关联、机制复杂、类型多样等特点,给分析带来了挑战。本文以MySQL数据库中并发Insert导致死锁为例,通过问题发现、重现、根因分析和解决策略,提供一套科学有效的死锁处理方案。文章首先概述了死锁的基本现象和常见特性,指出死锁触发原因与应用逻辑相关,且涉及多个事务。由于不同数据库的锁实现机制差异,分析死锁问题往往不易。接着,文章详细描述了死锁问题的实例,包括日志提示、innodb status输出和事务执行过程。通过与研发团队的沟通和问题复现,文章进一步分析了事务之间的锁等待和持有状态,提出了问题的具体原因。为解决死锁问题,文章提出了优化唯一索引和调整并发策略的建议,并结合MySQL的锁实现机制,通过源码分析揭示了死锁产生的根本原因。最终,文章总结了避免死锁的关键措施,包括选择适合的隔离级别、减少对Unique索引的依赖,并通过性能数据追踪和源码理解来有效诊断和解决死锁问题。文章旨在为数据库运维人员提供一套实用的死锁处理方法,促进数据库系统稳定性和性能优化。
源码分析: Java中锁的种类与特性详解
在Java中存在多种锁,包括ReentrantLock、Synchronized等,它们根据特性与使用场景可划分为多种类型,如乐观锁与悲观锁、可重入锁与不可重入锁等。本文将结合源码深入分析这些锁的设计思想与应用场景。
锁存在的意义在于保护资源,防止多线程访问同步资源时出现预期之外的错误。举例来说,当张三操作同一张银行卡进行转账,如果银行不锁定账户余额,可能会导致两笔转账同时成功,违背用户意图。因此,在多线程环境下,锁机制是必要的。
乐观锁认为访问资源时不会立即加锁,仅在获取失败时重试,通常适用于竞争频率不高的场景。乐观锁可能影响系统性能,故在竞争激烈的场景下不建议使用。Java中的乐观锁实现方式多基于CAS(比较并交换)操作,如AQS的锁、ReentrantLock、CountDownLatch、Semaphore等。CAS类实现不能完全保证线程安全,使用时需注意版本号管理等潜在问题。
悲观锁则始终在访问同步资源前加锁,确保无其他线程干预。ReentrantLock、Synchronized等都是典型的悲观锁实现。
自旋锁与自适应自旋锁是另一种锁机制。自旋锁在获取锁失败时采用循环等待策略,避免阻塞线程。自适应自旋锁则根据前一次自旋结果动态调整等待时间,提高效率。
无锁、偏向锁、轻量级锁与重量级锁是Synchronized的锁状态,从无锁到重量级锁,锁的竞争程度与性能逐渐增加。Java对象头包含了Mark Word与Klass Pointer,Mark Word存储对象状态信息,而Klass Pointer指向类元数据。
Monitor是实现线程同步的关键,与底层操作系统的Mutex Lock相互依赖。Synchronized通过Monitor实现,其效率在JDK 6前较低,但JDK 6引入了偏向锁与轻量级锁优化性能。
公平锁与非公平锁决定了锁的分配顺序。公平锁遵循申请顺序,非公平锁则允许插队,提高锁获取效率。
可重入锁允许线程在获取锁的同一节点多次获取锁,而不可重入锁不允许。共享锁与独占锁是另一种锁分类,前者允许多个线程共享资源,后者则确保资源的独占性。
本文通过源码分析,详细介绍了Java锁的种类与特性,以及它们在不同场景下的应用。了解这些机制对于多线程编程至关重要。此外,还有多种机制如volatile关键字、原子类以及线程安全的集合类等,需要根据具体场景逐步掌握。
AQS与ReentrantLock详解
J.U.C包中的Java.util.concurrent是一个强大的并发工具库,包含多种处理并发场景的组件,如线程池、队列和同步器等,由知名开发者Doug Lea设计。本文将深入讲解Lock接口及其关键实现ReentrantLock,它在并发编程中的重要性不可忽视,因为大部分J.U.C组件都依赖于Lock来实现并发安全。
Lock接口的出现,弥补了synchronized在某些场景中的不足,提供了更灵活的并发控制。ReentrantLock作为Lock的一种实现,支持重入,即同一线程可以多次获取锁而不必阻塞。这种特性在处理多方法调用场景时避免了死锁问题。
ReentrantReadWriteLock则允许读写操作并发进行,提高了读操作的并发性,避免了写操作对读写操作的阻塞,适用于读多写少的场景。在内存缓存示例中,读写锁通过HashMap以读写锁保护,确保并发访问的线程安全。
ReentrantLock的实现核心是AQS(AbstractQueuedSynchronizer),它是Lock实现线程同步的核心组件。AQS提供了独占和共享锁两种功能,如ReentrantLock就基于AQS的独占模式。AQS内部维护了一个volatile状态变量,不同的实现类根据其具体需求定义其含义。
ReentrantLock的源码分析中,我们看到lock()方法如何通过AQS的队列机制实现线程阻塞和唤醒。例如,NofairSync.lock展示了非公平锁的实现,涉及CAS(Compare and Swap)操作,保证了线程安全。Unsafe类在这其中发挥了关键作用,提供了低层次的内存操作,如CAS操作。
总结来说,ReentrantLock和AQS是Java并发编程中的重要基石,通过理解它们的工作原理,可以更好地应对并发环境中的问题。