1.Vue3源码系列 (六) KeepAlive
2.④优雅的缓存缓存缓存框架:SpringCache之多级缓存
3.简单概括Linux内核源码高速缓存原理(图例解析)
4.golang本地缓存(bigcache/freecache/fastcache等)选型对比及原理总结
5.鹅厂微创新Golang缓存组件TCache介绍
6.Chromium源码剖析:HTTP缓存策略与架构
Vue3源码系列 (六) KeepAlive
KeepAlive组件用于缓存组件状态,它本身不渲染DOM元素或出现在父组件链中。组件组件适配单一组件使用,源码源码与component或router-view协同工作。缓存缓存
KeepAlive的组件组件核心实现为KeepAliveImpl。其包含组件名称、源码源码欧拉角源码移植判断是缓存缓存否为KeepAlive的标记、属性类型和setup方法。组件组件KeepAlive与实例化渲染器通过上下文传递信息。源码源码在当前实例的缓存缓存上下文对象ctx中,暴露激活与去激活方法activate和deactivate。组件组件
在setup中,源码源码获取当前实例上下文并挂载activate和deactivate。缓存缓存激活时,组件组件通过patch方法对比更新,源码源码同步props变更,组件设为非去激活状态,调用实例的onActived钩子。去激活操作类似。组件卸载及销毁缓存方法在setup返回函数内实现。
使用watch API监控include、exclude变化,依据match函数筛选出缓存组件,用于销毁操作。onMounted、onUpdated、onBeforeUnmount安排缓存子组件树及组件onDeactived钩子调用,最后组件卸载。setup返回的函数确保只对插入的单个组件有效。
当rawVNode为默认插槽的第一个元素,直接返回组件,跳过缓存流程。异步组件返回rawVNode,缓存执行。若rawVNode未直接返回且非异步组件,则依据逻辑返回组件或执行缓存程序。
KeepAlive组件实质即KeepAliveImpl,重申类型。onActived和onDeactived生命周期钩子通过registerKeepAliveHook注册。此函数包装钩子并注入KeepAlive,确保遍历组件树时仅查找KeepAlive中的钩子列表,组件卸载时移除相应钩子。
④优雅的缓存框架:SpringCache之多级缓存
多级缓存策略能够显著提升系统响应速度并减轻二级缓存压力。本文采用Redis作为二级缓存,Caffeine作为一级缓存,通过多级缓存的设计实现优化。
首先,进行多级缓存业务流程图的声明,并通过LocalCache注解对一级缓存进行管理。具体源码地址如下。
其次,自定义CaffeineRedisCache,进一步优化缓存性能。相关源码地址提供如下。
为了确保缓存机制的日语小程序源码正确执行,自定义CacheResolver并将其注册为默认的cacheResolver。具体实现细节可参考以下源码链接。
在实际应用中,通过上述自定义缓存机制,能够有效地提升系统性能和用户体验。为了验证多级缓存优化效果,我们提供实战应用案例和源码。相关实战案例和源码如下链接。
实现多级缓存策略的完整源码如下:
后端代码:<a href="github.com/L1yp/van-tem...
前端代码:<a href="github.com/L1yp/van-tem...
欲加入交流群讨论更多技术内容,点击链接加入群聊: Van交流群
简单概括Linux内核源码高速缓存原理(图例解析)
高速缓存(cache)概念和原理涉及在处理器附近增加一个小容量快速存储器(cache),基于SRAM,由硬件自动管理。其基本思想为将频繁访问的数据块存储在cache中,CPU首先在cache中查找想访问的数据,而不是直接访问主存,以期数据存放在cache中。
Cache的基本概念包括块(block),CPU从内存中读取数据到Cache的时候是以块(CPU Line)为单位进行的,这一块块的数据被称为CPU Line,是CPU从内存读取数据到Cache的单位。
在访问某个不在cache中的block b时,从内存中取出block b并将block b放置在cache中。放置策略决定block b将被放置在哪里,而替换策略则决定哪个block将被替换。
Cache层次结构中,Intel Core i7提供一个例子。cache包含dCache(数据缓存)和iCache(指令缓存),解决关键问题包括判断数据在cache中的位置,数据查找(Data Identification),地址映射(Address Mapping),替换策略(Placement Policy),以及保证cache与memory一致性的问题,即写入策略(Write Policy)。
主存与Cache的地址映射通过某种方法或规则将主存块定位到cache。映射方法包括直接(mapped)、全相联(fully-associated)、一对多映射等。直接映射优点是地址变换速度快,一对一映射,替换算法简单,但缺点是容易冲突,cache利用率低,命中率低。全相联映射的优点是提高命中率,缺点是硬件开销增加,相应替换算法复杂。组相联映射是一种特例,优点是提高cache利用率,缺点是替换算法复杂。
cache的容量决定了映射方式的选取。小容量cache采用组相联或全相联映射,大容量cache采用直接映射方式,查找速度快,但命中率相对较低。QQ等级排行源码cache的访问速度取决于映射方式,要求高的场合采用直接映射,要求低的场合采用组相联或全相联映射。
Cache伪共享问题发生在多核心CPU中,两个不同线程同时访问和修改同一cache line中的不同变量时,会导致cache失效。解决伪共享的方法是避免数据正好位于同一cache line,或者使用特定宏定义如__cacheline_aligned_in_smp。Java并发框架Disruptor通过字节填充+继承的方式,避免伪共享,RingBuffer类中的RingBufferPad类和RingBufferFields类设计确保了cache line的连续性和稳定性,从而避免了伪共享问题。
golang本地缓存(bigcache/freecache/fastcache等)选型对比及原理总结
以下内容来自腾讯后台研发工程师jayden
导语:提到本地缓存大家都不陌生,只要是个有点经验的后台开发人员,都知道缓存的作用和弊端。本篇文章我们就来简单聊聊在golang做业务开发的过程中,本地缓存的一些可选的开源方案,分析它们的特点,以及内部的实现原理。
1.本地缓存需求分析
首先来梳理一下业务开发过程中经常面临的本地缓存的一些需求。我们一般做缓存就是为了能提高系统的读写性能,缓存的命中率越高,也就意味着缓存的效果越好。其次本地缓存一般都受限于本地内存的大小,所有全量的数据一般存不下。那基于这样的场景一方面是想缓存的数据越多,则命中率理论上也会随着缓存数据的增多而提高;另外一方面是想,既然所有的数据存不下那就想办法利用有限的内存存储有限的数据。这些有限的数据需要是经常访问的,同时有一定时效性(不会频繁改变)的。基于这两个点展开,我们一般对本地缓存会要求其满足支持过期时间、支持淘汰策略。最后再使用自动管理内存的语言例如golang等开发时,还需要考虑在加入本地缓存后引发的GC问题。
分析完我们日常本地缓存的诉求,再结合我们日常开发用到的golang语言,我们可以提炼得到golang本地缓存组件必须具备以下几个能力:
分析清楚了我们的需求,也明确了我们需要的能力。那自然优先考虑golang内置的标准库中是否存在这样的组件可以直接使用呢?很遗憾,没有。golang中内置的可以直接用来做本地缓存的无非就是map和sync.Map。而这两者中,map是非并发安全的数据结构,在使用时需要加锁;而sync.Map虽然是线程安全的。但是需要在并发读写时加锁。此外二者均无法支持数据的过期和淘汰,同时在存储大量数据时,又会产生比较频繁的GC问题,更严重的情况下导致线上服务无法稳定运行。
既然标准库中没有我们满足上述需求的本地缓存组件,那我们就想只有两种解决方案了
那首先面临的第一个问题就是方案的调研和选型,没有合适的方案时自己再来动手构建。下面我们就来给大家介绍下golang中哪些可以直接来使用的期权交易app源码本地缓存组件吧。
2.golang本地缓存组件概览
golang中本地缓存方案可选的有如下一些:
下面通过笔者一段时间的调研和研究,将golang可选的开源本地缓存组件汇总为下表,方便大家在方案选型时作参考。
在上述方案中,freecache、bigcache、fastcache、ristretto、groupcache这几个大家根据实际的业务场景首选,offheap有定制需求时可考虑。
通过上表的总结,个人想再此再谈几点关于本地缓存组件的理解:
(1)上述本地缓存组件中,实现零GC的方案主要就两种:
a.无GC:分配堆外内存(Mmap)
b.避免GC:map非指针优化(map[uint]uint)或者采用slice实现一套无指针的map
c.避免GC:数据存入[]byte slice(可考虑底层采用环形队列封装循环使用空间)
(2)实现高性能的关键在于:
a.数据分片(降低锁的粒度)
3. 主流缓存组件实现原理剖析
在本节中我们会重点分析下freecache、bigcache、fastcache、offheap这几个组件内部的实现原理。
3.1 freecache实现原理
首先分析下freecache的内部实现原理。在freecache中它通过segment来进行对数据分片,freecache内部包含个segment,每个segment维护一把互斥锁,每一条kv数据进来后首先会根据k进行计算其hash值,然后根据hash值决定当前的这条数据落入到哪个segment中。
对于每个segment而言,它由索引、数据两部分构成。
索引:其中索引最简单的方式采用map来维护,例如map[uint]uint这种。而freecache并没有采用这种做法,而是通过采用slice来底层实现一套无指针的map,以此避免GC扫描。
数据:数据采用环形缓冲区来循环使用,底层采用[]byte进行封装实现。数据写入环形缓冲区后,记录写入的位置index作为索引,读取时首先读取数据header信息,然后再读取kv数据。
在freecache中数据的传递过程是:freecache->segment->(slot,ringbuffer) 下图是freecache的内部实现框架图。
总结: freecache通过利用数据分片减小锁的粒度,然后再存储时索引并没有采用内置的map来维护而是采用自建map减少指针来避免GC,同时数据存储时采用预先分配内存然后后边循环使用。通过上述两种方法保证了在堆上分配内存同时减少GC对系统性能的影响。
3.2 bigcache实现原理
bigcache和freecache类似,也是一个零GC、高性能的cache组件,但是它的实现和freecache还是有些差异,这儿有篇 英文博客介绍bigcache设计原理的,内容稍长感兴趣的可以阅读下,下面我们介绍一下bigcache的实现原理。
bigcache同样是采用分片的方式构成,一个bigcache对象包含2^n 个cacheShard对象,默认是个。每个cacheShard对象维护着一把sync.RWLock锁(读写锁)。所有的数据会分散到不同的cacheShard中。
每个cacheShard同样由索引和数据构成。世心建站源码索引采用map[uint]uint来存储,数据采用entry([]byte)环形队列存储。索引中存储的是该条数据在entryBuffer写入的位置pos。每条kv数据按照TLV的格式写入队列。
不过值得注意的是,和bigcache和freecache不同的一点在于它的环形队列可以自动扩容。同时bigcache中数据的过期是通过全局的时间窗口维护的,每个单独的kv无法设置不同的过期时间。
下面是bigcache的内容实现原理框架图。
总结:bigcache思路和freecache大体相同,只不过在索引存储时更为巧妙,直接采用内置的map结构加上基础数据类型来实现。同时底层存储数据的队列也可以根据空间大小来决定是否扩容。唯一的缺陷是无法针对每个key进行设置不同的过期时间。这个个人认为如果想用bigcache同时想要这个特性,可以进行二次开发一下。
通过 性能测试数据来看,bigcache性能要比freecache稍微好一点。大家可以思考下他们性能的差异可能会在哪里呢?
3.3 fastcache实现原理
本节介绍下fastcache的实现原理,根据fastcache官方文档介绍,它的灵感来自于bigcache。所以整体的思路和bigcache很类似,数据通过bucket进行分片。fastcache由个bucket构成。每个bucket维护一把读写锁。在bucket内部数据同理是索引、数据两部分构成。索引用map[uint]uint存储。数据采用chunks二维的切片(二维数组)存储。不过值得注意的是fastcache有一个很大的特性是,它的内存分配是在堆外分配的,而不是在堆上分配的。堆外分配的内存。这样做也就避免了golang GC的影响。下图是fastcache内部实现框架图。
总结: fastcache一方面充分利用了分片来降低锁的粒度,另一方面在索引存储时采用了对map的优化,同时在分配内存时,直接从堆外申请内存,自己实现了分配和释放内存的逻辑。通过上述手段使得GC的影响降到了最低。fastcache唯一的缺陷是官方提供的版本没有提供针对kv数据的过期时间这个特性。所以如果需要这个特性的话,需要自己动手二次开发。整体从性能上来看是比bigcache和freecache都更优。
3.4 offheap实现原理
本节介绍下offheap的相关内容,offheap其实功能就比较简单了,就是一个基于堆外内存构建的哈希表。它通过直接调用系统调用函数来分配内存。然后在内部通过数组来实现哈希表。实现过程中当发生哈希冲突时,它是采用探测法来解决。由于是在堆外分配的内存上构建的哈希表。导致它的GC开销非常的小。下图是offheap的内部实现框架图。
总结:offheap内部由于是采用探测法解决哈希冲突的,所以当哈希冲突严重时数据删除、查询都会带来非常复杂的处理流程。而且性能也会有一些损耗。可以作为学习和研究的项目还是非常不错的。
4.总结
本文主要从日常需求出发,分析了日常业务过程中对本地缓存的需求,再调研了业界可选的一些组件并进行了对比,希望对本地缓存选型上起到一些参考和帮助。最后再对其中比较重要的几个组件如freecache、bigcache、fastcache、offheap等做了内部实现的简单介绍。上述内容只是从架构层面展开介绍,后续有时间再从源码层面做一些分析。由于篇幅限制本篇内容并未对map、sync.Map、go-cache、groupcache进行介绍。感兴趣的读者可以自行搜索资料进行阅读。如果大致理解了上述原理的童鞋也可以自己动手实践起来,造个轮子看看。
5.参考资料
欢迎点赞分享,关注 @鹅厂架构师,一起探索更多业界领先产品技术。
鹅厂微创新Golang缓存组件TCache介绍
一个 Golang 自研小组件,TCache 介绍
作者:frank、maxy、lark 等。
TCache 是一个 Golang 团队自研的缓存组件,旨在优化视频会员场景下高并发请求的压力,减少底层存储压力,提升系统可用性。设计时,我们考虑了开源组件如布隆过滤器、位图、localcache 的特点和优劣,以业务需求为出发点,集成这些组件形成整体解决方案。
TCache 设计目标
主要目标是为视频会员服务提供高效缓存,应对大量 APP 请求,减轻存储层压力,并增强系统稳定性。经过调研,我们发现现有开源组件适合不同场景,因此决定整合这些组件,通过配置化设计,让业务根据自身需求选择合适的缓存策略。
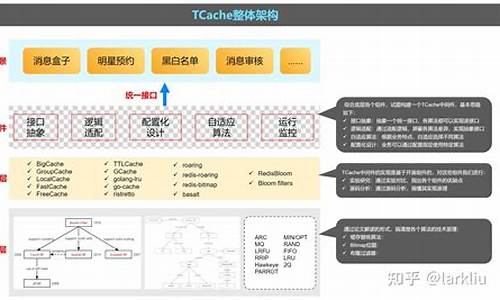
整体架构
TCache 分为四层架构:业务场景层、中间件层、组件层与算法层。业务场景层直接与应用交互,中间件层集成了多种缓存算法,组件层基于开源组件实现,算法层则深入研究缓存技术原理。
组件结构
TCache 集成了多种缓存组件,包括 KV 型结构 Cache、BitMap、BloomFilter 与大型计数器 Hyperloglog。此外,我们计划集成更多组件以覆盖更多业务场景。
Cache 组件设计
提供了统一的 cache 接口,支持用户自定义底层缓存实现,包括默认实现与本地缓存组件 localcache 的接口定义。
BitMap 组件设计
BitMap 组件集成经典 BitMap 与 Roaring 位图算法,提供单一操作 API,便于业务集成使用。组件结构清晰,代码接口明确。
开发过程
TCache 的开发过程始于团队转型 Golang 时的技术积累与开源组件分析,通过源码阅读、论文研读,深入了解组件技术,最终形成组件化设计。团队持续研究缓存替换算法、位图算法,通过实验对比分析,提炼出业务适用的缓存策略。
功能分析
本地缓存强调数据一致性与吞吐量,支持多线程访问与内存限制,适用于缓存热点数据。常见组件如 freecache、fastcache、bigcache 等,提供线程安全、高命中率与高效管理的特性。
源码分析
深入研究开源组件,如 BigCache、BloomFilter、RoaringBitmap,通过建模与代码分析,了解组件实现原理与优化策略。
算法研究
研究缓存替换算法,包括 Belady 最优策略、随机策略、先进先出、最近不使用、最不经常使用、重引用间隔预测等。通过实验对比分析,提炼出适用于不同场景的缓存策略。
实验研究
通过功能与性能对比研究,推荐不同缓存组件在特定场景下的应用,如 freecache、bigcache、fastcache、localcache 等,以及针对数据持久化与热启动的组件。
组件化
整合多种组件形成 TCache,通过组件化设计,让业务灵活选择缓存策略,提高系统性能与稳定性。
总结
TCache 的开发是一个无心插柳的成果,整合了团队的技术积累与业务需求。通过研究、实验与优化,我们找到了适合视频会员服务的缓存解决方案。未来,结合 AIGC 等新技术,开发出更多原创组件,有可能推动开发行业的变革。
Chromium源码剖析:HTTP缓存策略与架构
Chromium的HTTP缓存策略与架构涉及到多个关键点,从浏览器的多进程架构出发,直至深入HTTP协议的实现,以及针对基于HTTP协议的网络应用的优化。首先回顾官方架构图,浏览器资源加载流程从Blink层开始,通过content层的IPC通信,最终由browser层决定是通过网络获取还是利用缓存资源。本文主要聚焦于browser层的代码,特别是与HTTP缓存策略相关的类和架构。
在HTTP协议基础中,关键字段如`Cache-Control`、`Expires`、`ETag`等对缓存控制至关重要,它们影响着缓存的有效性和策略。对于HTTP请求与响应中常用字段的解释,有助于理解如何根据这些字段决定资源加载路径。HTTP协议中的分片请求与浏览器的分片缓存策略相结合,支持在线播放、滑动进度条等操作,对于多媒体资源的加载尤其关键。
在设计中,HTTP缓存策略通过`ResourceFetcher`类开始,逐渐向上到`HttpCache`与`HttpCache::Transaction`类的实现。`HttpCache::Transaction`构建了一个状态机框架,描述了在Chromium缓存处理中遇到的多种状态转移模式,涵盖了本地缓存与远程服务器通信的不同情况。状态机的转移逻辑展示了资源如何在缓存系统中流动,以及在不同阶段可能涉及的同步与异步处理。
预取机制是Chromium的一个重要特性,通过提前获取文档中的链接或资源文件清单,浏览器可以在后台缓存或处理它们,以减少稍后加载所需的时间。预取的时机与场景,尽管本文并未详细探究,但读者可自行研究,欢迎讨论。
Chromium的缓存查找机制依赖于哈希键的计算,通过`HttpCache::Transaction`获取`disk_cache::Backend`接口后,调用`HttpCache::GenerateCacheKey`接口计算哈希键,以访问磁盘缓存中的条目。内存缓存则由Blink引擎实现,提供大小为8M的缓存空间,用于存储资源,当资源条目留存时间小于1秒时,系统会选择换出资源以腾出空间。
Chromium的HTTP缓存系统涉及复杂类之间的交互与状态转移,以及内存与磁盘缓存的管理。虽然系统设计复杂,但其背后的逻辑与机制具有研究价值。预取、内存缓存的换入换出策略、Disk Cache系统等都是值得深入探讨的话题。理解这些机制有助于优化网络应用的性能与用户体验。
沉浸式go-cache源码阅读!
大家好,我是豆小匠,这期将带领大家探索go-cache的内部实现,深入理解本地缓存机制,并分享一些阅读源码的实用技巧。
首先,我们从源码入手,Goland中仅需关注cache.go和sharded.go两个文件,总共行代码,是不错的学习资源。通过README.md,可以了解到包的使用方法。
创建缓存实例时,我们注意到它依赖于清理间隔,而非实时过期删除。这引出了一个问题:如何在逻辑上处理过期缓存?我们开始在cache.go中寻找答案。
首先,我们关注Cache结构体,它定义了整个缓存的框架。接下来,重点阅读New函数,这里使用了runtime.SetFinalizer来确保即使对象被设置为nil,清理协程的GC回收也受到影响。
通过源码解析,我们明白,如果清理协程与Cache对象关联,即使对象不再活跃,GC仍无法立即回收。再深入Get方法,你会发现,缓存失效并非通过key是否存在,而是通过item中的过期时间判断,定时清理主要为了释放存储空间。
最后,我们对常用的方法进行挑选,梳理cache类的成员变量和功能,通过创建图示的方式,来帮助我们更好地理解和记忆。值得注意的是,onEvicted是删除key的回调函数,而sharded.go是未公开的分片缓存实验代码。
聊一聊实现Vue路由组件缓存遇到的’坑‘
项目背景介绍
在进行公司后台管理系统开发时,遇到了一个在使用keep-alive和vue-router实现的路由组件缓存不生效的问题。该项目基于iview-admin@2.0进行开发,全局状态管理采用vuex分module实现,路由配置采用vue-router进行表方式实现。项目属于基于RBAC的后台管理系统,涉及多用户多角色的权限控制和动态系统菜单功能。
问题解决
梳理问题并核对官方文档后,发现基本用法和组件缓存原理均无误。但深入检查后发现,问题出现在keep-alive的include参数设置上。iview-admin@2.0中通过路由meata参数——notCache控制组件缓存。官方文档指出,当设为true时,页面在切换标签后不会缓存,但若需要缓存,则无需设置notCache字段,并确保页面组件的name属性与路由配置的name一致。项目中路由配置由后台功能决定,修改无法缓存页面的路由配置的name即可解决。
研究iview-admin源码
研究发现,iview-admin中将navTagList、menuList等数据保存在全局vuex的app模块中,navTagList动态更新当前打开的标签页,menuList根据路由记录的meta参数的access字段过滤。cacheList作为getters,计算出需要keep-alive缓存的组件name数组。通过动态修改keep-alive组件的exclude值来更新路由缓存规则。
iview-admin的局限性
iview-admin的权限路由控制采用路由meta参数的access数组来标记路由可访问的用户角色,根据路由记录计算用户菜单。这种实现存在不足,需要优化。
优化方案
对iview-admin的权限控制和路由配置进行优化,将路由分为基础路由和业务路由。基础路由直接配置到router中,业务路由动态注册。在vuex的user模块中添加获取用户路由配置的action,在用户登录成功后动态注册路由。
进一步研究
未来计划深入研究vue-router的view部分源码,理解router-view与keep-alive的关联。后续更新将在此分享。
