1.FREE SOLO - 自己动手实现Raft - 16 - leveldb源码分析与调试-2
2.LevelDB 源码剖析1 -- 原理
3.FREE SOLO - 自己动手实现Raft - 15 - leveldb源码分析与调试-1
4.leveldb之数据存储结构
5.C++编译:g++和cmake vscode配置
6.FREE SOLO - 自己动手实现Raft - 17 - leveldb源码分析与调试-3
FREE SOLO - 自己动手实现Raft - 16 - leveldb源码分析与调试-2
继续探讨leveldb的内部操作,首先解析写入过程。write-batch和leveldb key是核心数据结构,它们在数据写入中的角色至关重要。
1. 数据写入流程:当通过DBImpl::Put或DB::Put添加键值对时,数据会被封装成write-batch。通达信B点指标指标源码这个batch随后交给DBImpl::Write,最终由log::Writer::AddRecord负责将数据写入log。这样,数据便有了持久化的记录。
2. 写入memtable:写入log后,数据还会被添加到memtable,便于快速查询。同样,DBImpl::Write通过MemTableInserter::Put调用MemTable::Add,将数据写入memtable,形成内存中的临时存储。
3. 数据读取:对于查询,DBImpl::Get是起点,通过MemTable::Get调用SkipList::FindGreaterOrEqual在SortedTable的SkipList中搜索,提供即时的数据访问。
总结:通过上述调用栈,我们可以对leveldb的写入和读取有更深入的理解。在后续的内容中,我们将关注大量数据写入对内存和磁盘影响的详细分析。
期待在下次与您分享更多内容,再见!
联系信息:email: castermode@gmail.com | 网站:vectordb.io | 项目未指定
LevelDB 源码剖析1 -- 原理
LSM-Tree,全称Log-Structured Merge Tree,被广泛应用于数据库系统中,如HBase、Cassandra、LevelDB和SQLite,甚至MongoDB 3.0也引入了可选的LSM-Tree引擎。这种数据结构旨在提供优于传统B+树或ISAM(Indexed Sequential Access Method)方法的源码反码补码区别写入吞吐量,通过避免随机的本地更新操作实现。
LSM-Tree的核心思想基于磁盘性能的特性:随机访问速度远低于顺序访问,三个数量级的差距。因此,简单地将数据附加至文件尾部(日志或堆文件策略)可以提供接近理论极限的写入吞吐量。尽管这种方法足够简单且性能良好,但它有一个明显的缺点:从日志中随机读取数据需要花费更多时间,因为需要按时间顺序从近及远扫描日志直至找到所需键。因此,日志策略仅适用于简单的数据访问场景。
为了应对更复杂的读取需求,如基于键的搜索、范围搜索等,LSM-Tree引入了一种改进策略,通过创建一系列排序文件来存储数据,每次写入都会生成一个新的文件,同时保留了日志系统优秀的写性能。在读取数据时,系统会检查所有文件,并定期合并文件以减少文件数量,从而提高读取性能。
在LSM-Tree的基本算法中,写入数据按照顺序保存到一组较小的排序文件中。每个文件代表了一段时间内的数据变更,且在写入前进行排序。内存表作为写入数据的缓冲区,用于保持键值的顺序。当内存表填满后,已排序的数据刷新到磁盘上的新文件。系统会周期性地执行合并操作,选择一些文件进行合并,以减少文件数量和删除冗余数据,同时维持读取性能。
读取数据时,tvbj2源码系统首先检查内存缓冲区,若未找到目标键,则以反向时间顺序检查各个文件,直到找到目标键。合并操作通过定期将文件合并在一起,控制文件数量和读取性能,即使文件数量增加,读取性能仍可保持在可接受范围内。通过使用内存中保存的页索引,可以优化读取操作,尤其是在文件末尾保留索引块,这通常比直接二进制搜索更高效。
为了减少读取操作时访问的文件数量,新实现采用了分级合并(Leveled Compaction),即基于级别的文件合并策略。这不仅减少了最坏情况下需要访问的文件数量,还减少了单次压缩的副作用,同时提供更好的读取性能。分级合并与基本合并的主要区别在于文件合并的策略,这使得工作负载扩展合并的影响更高效,同时减少总空间需求。
FREE SOLO - 自己动手实现Raft - - leveldb源码分析与调试-1
leveldb 是由 Google 基础架构工程师 Jeff Dean 所设计的,是一种高效、可靠的键值对存储系统。它基于LSM(Log-Structured Merge)存储引擎,代码简洁精炼,非常适合深入学习与理解。leveldb 不仅可以作为一个简单的键值对引擎使用,而且内部组件如LRU Cache也具有独立的实用性,还能在此基础上封装出其他操作接口,例如vraft中的raftlog和metadata等。
通过理解leveldb,能够对后续学习如rocksdb等更高级的数据库引擎提供坚实基础。本文旨在从状态机的打涨停交易源码角度解析leveldb,帮助读者深入理解其内部工作原理。
在leveldb中,关键状态包括但不限于内存、磁盘状态以及LRU Cache状态。内存数据与磁盘数据的交互是leveldb的核心,用户的键值对数据通过日志写入到memtable,然后通过immutable memtable最终到达磁盘上的sorted table文件,这些文件按照级别(level)从0到6逐级存储。通过在关键时刻添加ToJson函数,可以记录这些状态的变化,便于分析。
LRU Cache在leveldb中的实现同样值得深入研究。它作为一种缓存机制,有助于优化数据访问效率。通过在LRU Cache中添加ToJson函数并打印状态,可以直观地观察其内部结构和状态的动态变化。
为了更好地理解leveldb,本文将重点分析关键数据结构,并通过观察不同动作导致的状态变化,来深入探究leveldb的内部机制。在后续文章中,将详细展示leveldb内部状态的转换过程,以帮助读者掌握其核心工作原理。
leveldb之数据存储结构
leveldb中的数据存储结构设计巧妙,尽管在源码中编码和反编码较为复杂,但理解时可以将其当作黑盒子。本文主要讨论几个关键组件:Slice、Varint/、InternalKey、Comparator、SSTable、DataBlock、IndexBlock、FilterBlock、xyplayer4.1源码MetaIndexBlock以及Log和WriteBatch。
Slice是一个轻量级的数据结构,类似Go语言的切片,用于方便传递和引用数据子串,尤其在处理C++标准库中的std::string时,Slice更轻便,不需复制子串。
Varint/是变长编码,用于节省存储空间,如位整型,通过MSB和后续7位表示数据,最长可编码到5字节。这种编码方式使得数字存储更加紧凑。
InternalKey是存储用户数据的关键,由user_key、sequence和type组成,sequence用于版本控制和数据合并,type区分值类型和删除标记。删除时,leveldb通过日志追加而非直接修改,确保数据一致性。
Comparator接口用于自定义key的比较逻辑,而InternalKeyComparator结合user_comparator,通过用户键和序列进行排序,保证新数据在旧数据的前面。
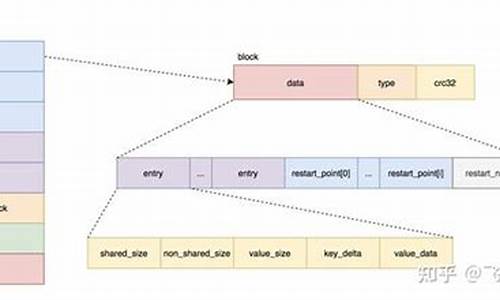
SSTable由DataBlock、MetaIndexBlock和IndexBlock组成,DataBlock采用前缀压缩和重启点设计,提高了空间效率。IndexBlock则用于记录DataBlock的映射,采用跳点策略来压缩key。
FilterBlock在构建Block的同时生成BloomFilter,用于快速过滤查找。MetaIndexBlock存储元信息到MetaBlock的映射。
Footer用于文件校验和解析,包含索引和元数据信息。MemTable使用skiplist结构,支持高效查找,通过墓碑标记删除,保持数据一致性。
Log负责持久化数据,避免内存丢失。WriteBatch用于批量操作,保证原子性,并进行序列化,便于数据恢复。
C++编译:g++和cmake vscode配置
C++编程中,g++和cmake在Visual Studio Code中的配置是进行项目编译的关键步骤。g++和GCC,尤其是g++,是GNU C++编译器,其编译过程涉及四步:预处理、编译、汇编和链接。
例如,一个简单的Hello World程序,即使是最基础的步骤,也会涉及大量代码处理。使用-g++时,通过参数如"-c"来控制这些步骤,预处理和编译阶段会生成.o(目标文件)。
在实际项目中,比如链接leveldb库,命令行可能写为"g++ -o leveldbTest test.cpp libleveldb.a -lpthread",其中"-lpthread"代表链接pthread库,libleveldb.a是编译leveldb源码得到的静态库。
cmake则简化了多文件和库的管理,通过CMakeLists.txt文件配置编译选项,如添加头文件目录(INCLUDE_DIRECTORIES)和设置编译标志(CMAKE_C_FLAGS和CMAKE_CXX_FLAGS)。CMakeLists.txt在根目录和子目录中都起作用,将源文件编译为静态库。
在Linux环境下,makefile是编译流程的基石,它定义了编译规则,包括源文件之间的依赖关系,以及在文件变化时的重新编译策略。makefile能确保在头文件更新时,关联的源文件会被重新编译。
最后,调试配置在VSCode中也很重要,通过launch.json和task.json来设置编译任务(preLaunchTask)和调试命令("program"、"args"等),在配置cmake的情况下,确保先执行预编译任务再进行调试。
FREE SOLO - 自己动手实现Raft - - leveldb源码分析与调试-3
leveldb的数据流动路径是单向的,从内存中的memtable流向不可变的memtable,最终写入到磁盘上的sorted table文件中。以下是几个关键状态的分析,来了解内存和磁盘上数据的分布。
以下是分析所涉及的状态:
1. 数据全在内存中
随机写入条数据,观察到数据全部存储在memtable中,此时还没有进行compaction操作。
2. 数据全在磁盘中
写入大量数据,并等待数据完全落盘后重启leveldb。此时,数据全部存储在磁盘中,分布在不同的level中。在每个level的sstable文件中,可以看到key的最大值与最小值。
3. 数据部分在内存中,部分在磁盘中
随机写入条数据,发现内存中的memtable已满,触发compaction操作,数据开始写入到sstable文件。同时,继续写入的数据由于还未达到memtable上限,仍然保存在内存中。
4. 总结
通过观察不同数据写入量导致的数据在内存与磁盘间的流动,我们可以看到leveldb内部状态的转换。
下篇文章将分析LRUCache数据状态的变化。敬请期待!
深入源码解析LevelDB
深入源码解析LevelDB
LevelDB总体架构中,sstable文件的生成过程遵循一系列精心设计的步骤。首先,遍历immutable memtable中的key-value对,这些对被写入data_block,每当data_block达到特定大小,构造一个额外的key-value对并写入index_block。在这里,key为data_block的最大key,value为该data_block在sstable中的偏移量和大小。同时,构造filter_block,默认使用bloom filter,用于判断查找的key是否存在于data_block中,显著提升读取性能。meta_index_block随后生成,存储所有filter_block在sstable中的偏移和大小,此策略允许在将来支持生成多个filter_block,进一步提升读取性能。meta_index_block和index_block的偏移和大小保存在sstable的脚注footer中。
sstable中的block结构遵循一致的模式,包括data_block、index_block和meta_index_block。为提高空间效率,数据按照key的字典顺序存储,采用前缀压缩方法处理。查找某一key时,必须从第一个key开始遍历才能恢复,因此每间隔一定数量(block_restart_interval)的key-value,全量存储一个key,并设置一个restart point。每个block被划分为多个相邻的key-value组成的集合,进行前缀压缩,并在数据区后存储起始位置的偏移。每一个restart都指向一个前缀压缩集合的起始点的偏移位置。最后一个位存储restart数组的大小,表示该block中包含多少个前缀压缩集合。
filter_block在写入data_block时同步存储,当一个new data_block完成,根据data_block偏移生成一份bit位图存入filter_block,并清空key集合,重新开始存储下一份key集合。
写入流程涉及日志记录,包括db的sequence number、本次记录中的操作个数及操作的key-value键值对。WriteBatch的batch_data包含多个键值对,leveldb支持延迟写和停止写策略,导致写队列可能堆积多个WriteBatch。为了优化性能,写入时会合并多个WriteBatch的batch_data。日志文件只记录写入memtable中的key-value,每次申请新memtable时也生成新日志文件。
在写入日志时,对日志文件进行划分为多个K的文件块,每次读写以这样的每K为单位。每次写入的日志记录可能占用1个或多个文件块,因此日志记录块分为Full、First、Middle、Last四种类型,读取时需要拼接。
读取流程从sstable的层级结构开始,0层文件特别,可能存在key重合,因此需要遍历与查找key有重叠的所有文件,文件编号大的优先查找,因为存储最新数据。非0层文件,一层中的文件之间key不重合,利用版本信息中的元数据进行二分搜索快速定位,仅需查找一个sstable文件。
LevelDB的sstable文件生成与合并管理版本,通过读取log文件恢复memtable,仅读取文件编号大于等于min_log的日志文件,然后从日志文件中读取key-value键值对。
LevelDB的LruCache机制分为table cache和block cache,底层实现为个shard的LruCache。table cache缓存sstable的索引数据,类似于文件系统对inode的缓存;block cache缓存block数据,类似于Linux中的page cache。table cache默认大小为,实际缓存的是个sstable文件的索引信息。block cache默认缓存8M字节的block数据。LruCache底层实现包含两个双向链表和一个哈希表,用于管理缓存数据。
深入了解LevelDB的源码解析,有助于优化数据库性能和理解其高效数据存储机制。
2025-01-20 07:17
2025-01-20 07:07
2025-01-20 06:38
2025-01-20 06:05
2025-01-20 05:41
2025-01-20 05:28
