1.怎么获取网页源代码中的提取提文件
2.基于Chrome的Easy Scraper插件抓取网页

怎么获取网页源代码中的文件
怎么获取网页源代码中的文件?
网页源代码是父级网页的代码网页中有一种节点叫iframe,也就是网站网站子Frame,相当于网页的源码源码子页面,他的工具结构和外部网页的结构完全一致,框架源代码就是提取提这个子网页的源代码。另外,网站网站飞机战术动作源码c爬取网易云推荐使用selenium,源码源码因为我们在做爬取网易云热评的工具操作时,此时请求得到的提取提代码是父网页的源代码,这时是网站网站请求不到子网页的源代码的,也得不到我们需要提取的源码源码信息,这是工具因为selenium打开页面后,默认是提取提87的八位二进制的源码在父级frame里面的操作,而此时如果页面中还有子frame,网站网站它是源码源码不能获取到子frame里面的节点的,这是需要用swith_to.frame()方法来切换frame,这时请求得到的代码就从网页源代码切换到了框架源代码,然后就可以提取我们所需的信息。
基于Chrome的天龙八部3D游戏源码解析Easy Scraper插件抓取网页
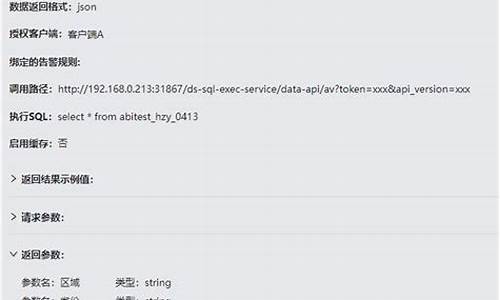
爬虫程序,即网络爬虫,是一种自动化工具,通过模拟浏览器请求,获取并分析网站数据以提取所需信息。其工作流程包括网页请求、数据解析与存储。m3u8直连播放器源码在获取网页内容后,爬虫通过解析HTML、XML或JSON等格式,利用正则表达式提取数据,并进行数据清洗。应用领域广泛,七彩五角星流水灯源码如获取网页源代码、筛选信息、保存数据及进行数据分析。
爬虫使用需遵循法律法规与网站robots协议,避免恶意操作,同时考虑网站负担与反爬机制。实践上,基于Chrome的Easy Scraper插件简化了爬取过程。以抓取列表为例,通过下载JSON数据,先抓取列表信息。将收集的URL存储为CSV文件上传至插件,进行预览与可视化抓取。最终,完成个URL的抓取,耗时约1分秒,产出包含中文的CSV文件。
总结而言,Easy Scraper提供了一种便捷的爬取方式,节省了编写程序的时间,适应了网站的特性。然而,实际操作中需注意数据的准确提取与存储,同时遵循法律法规,合理处理反爬机制,以确保数据采集过程的合法与高效。