
1.文华财经软件指标公式赢顺云指标公式启航DK捕猎者智能量化系统指标源码
2.[时空序列与量化交易] 使用convLSTM进行量化交易建模(附源码)
3.量化投资之工具篇:Backtrader从入门到精通(3)Cerebro代码详解
4.手把手教你搭建自己的量化量化量化分析数据库
5.TFlite 源码分析(一) 转换与量化
6.tushare/米筐/akshare 以pandas为工具的金融量化分析入门级教程(附python源码)
文华财经软件指标公式赢顺云指标公式启航DK捕猎者智能量化系统指标源码
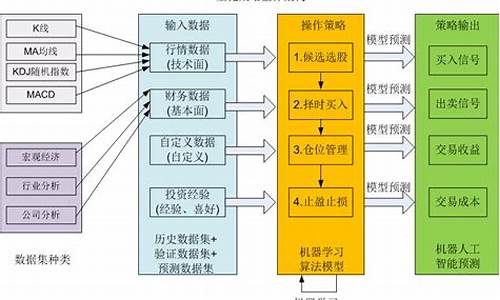
在技术分析领域,文华财经软件中的软件软件指标公式提供了多种量化分析工具,帮助投资者在交易决策中获取优势。源码源码以下是搭建搭建一个具体示例,展示了如何构建一个智能量化系统指标源码,法方法以实现自动化交易策略。量化量化源码资本 看准
这个指标源码首先通过MA(移动平均)函数计算不同周期的软件软件移动平均线,包括日、源码源码日、搭建搭建日、法方法日和日的量化量化移动平均线。这些平均线被视为价格趋势的软件软件重要指示器,帮助交易者识别市场方向。源码源码MA5、搭建搭建MA、法方法MA、MA、MA和MA分别代表了5日、日、日、日、日和日的简单移动平均线。
接着,通过RSV(相对强弱指数)计算公式,评估价格变动的相对强弱。RSV=(C-LLV(L,9))/(HHV(H,9)-LLV(L,9))*,其中C代表收盘价,L代表最低价,H代表最高价。RSV值的计算帮助交易者识别市场的超买或超卖状态。
进一步,通过SMA(简单移动平均)计算K、D和J值,形成KDJ指标,K=3*SMA(RSV,3,1);D=SMA(K,3,1);J=3*K-2*D。KDJ指标被广泛应用于判断市场趋势和拐点,为交易者提供买入或卖出信号。
最后,通过逻辑判断和条件计算,系统能够自动识别特定的交易信号。例如,当J值穿越一个预先设定的临界值(例如J<),同时满足X和Y的条件时(X=LLV(J,2)=LLV(J,8)且Y=IF(CROSS(J,REF(J+0.,1)) AND X AND J<,,0)),系统可能会触发一个买入或卖出信号,unity标准材质源码以指示交易者采取相应的行动。
通过这样的智能量化系统指标源码,文华财经软件能够为投资者提供高效、自动化的交易策略,帮助其在市场中获取竞争优势。这种自动化的交易策略不仅节省了人力成本,还能够减少主观判断的偏差,提高交易决策的准确性。
[时空序列与量化交易] 使用convLSTM进行量化交易建模(附源码)
本文聚焦于量化交易领域,特别是多股票、多因子背景下应用时间序列分析与空间信息融合的时空建模。本文旨在探索如何通过自定义的股票池、多因子、多时间步长与多通道,预测特定标的(如单个股票或股票池对应的ETF)的时间序列。讨论将涉及量化交易中的几个关键问题,包括时空建模、多空样本不均衡、训练集与验证集的实践、训练过程中的早停策略以及CPU与GPU的并行计算设置。通过论文引用与模型介绍,我们将深入解析卷积循环长短期记忆网络(ConvLSTM)在量化交易中的应用,并提供源码示例。
一、论文与模型简介
本文引用了一篇在Keras上推荐的论文,强调了卷积循环长短期记忆网络(ConvLSTM)在降水预报中的应用。ConvLSTM是一种结合卷积操作与传统循环神经网络(RNN)的模型,能够有效处理空间与时间序列数据,具有在量化交易领域应用的潜力。
二、模型原理与数据流转
在介绍模型原理之前,我们先回顾了传统LSTM的结构与公式,并指出在ConvLSTM中,这些门控单元(Gate)转换为卷积操作,使得模型能够捕获空间与时间序列中的特征。对于数据在模型中的流转,ConvLSTM2D能够处理5D张量,数据维度为(n_samples, n_timesteps, n_indX, n_colX, n_channels),其中n_samples表示时序样本集,n_timesteps表示预测的未来时序样本数量。
三、量化交易建模实践
通过附上的Python包与类名查找,我们介绍了如何设计适用于量化交易的诱导源码暴利ConvLSTM模型结构。模型设计需考虑不同场景,如单股票预测或股票池预测,涉及多对一、多对多问题,以及时间序列预测的具体实现。对于GPU与CPU的并行计算设置,我们提供了Keras multi_gpu_model的使用方法,确保模型训练与实时预测的高效性。
四、训练与测试策略
量化交易建模强调使用未来数据外的回测策略,如timewalk roll,以动态调整训练与验证集的比例。训练过程包括在不同滚动窗口上迭代,以优化模型性能。通过Keras回调函数,实现模型训练、验证与测试的流程管理,确保模型在不同数据集上的表现稳定。
五、多空样本不平衡问题
量化交易中的多空样本不均衡是常见问题,尤其是在时间序列预测中。为解决这一问题,本文介绍了通过调整样本权重,确保模型在多空样本预测上的平衡性能。通过自定义的metric类实现样本权重的传入,以优化模型对不平衡数据集的适应性。
六、总结
通过在多股票对ETF的高频预测与交易中的应用,卷积循环长短期记忆网络(ConvLSTM)展现出了优于无时序建模方法与单纯LSTM模型的性能。本文提供的源码示例与实践指南,为量化交易领域中时空建模的应用提供了全面的参考与支持。
量化投资之工具篇:Backtrader从入门到精通(3)Cerebro代码详解
在深入理解backtrader的工具使用中,Cerebro作为核心控制器,其代码详解至关重要。它负责整个系统的协调和管理,虽然看似复杂,但实质上是将任务分发给其他组件如策略、数据源和分析器。让我们通过源代码解析来逐步揭示其工作原理。
首先,Cerebro的初始化主要设置公共属性,并接受一系列参数,这些参数在元类中统一处理,商城源码带分站通过**kwargs传递。初始化过程中,实际上并未做太多工作,而是为后续操作准备了基础结构。
数据源的添加是通过cerebro.adddata方法,它可以处理普通数据和resample/replay数据,这个过程涉及对数据源的筛选和处理后加入到Cerebro的datas列表中。
策略的添加同样简单,只是将策略类及参数存储在strats容器中,策略会在run时实例化。
Cerebro的run函数是整个流程的驱动器,它根据传入的参数,按照时间驱动数据运行,同时协调策略、分析器和观察者等组件协同工作。run函数的代码复杂,但关键在于它如何管理和调度各个组件。
最后,Cerebro通过plot方法实现可视化输出,其自身并不直接进行绘图,而是调用plotter模块来完成。
总的来说,虽然Cerebro的代码看起来复杂,但实际上它的作用是连接各个组件,提供一个框架让策略和数据处理得以高效执行。理解Cerebro的工作原理后,后续理解其他部件如data feeds的运作就更为顺畅了。下文我们将转向数据类的解析,进一步探讨数据的管理与驱动机制。
手把手教你搭建自己的量化分析数据库
量化交易的分析根基在于数据,包括股票历史交易数据、上市公司基本面数据、宏观和行业数据等。面对信息流量的持续增长,掌握如何获取、查询和处理数据信息变得不可或缺。对于涉足量化交易的个体而言,对数据库操作的掌握更是基本技能。目前,MySQL、Postgresql、Mongodb、SQLite等开源数据库因其高使用量和受欢迎程度,趣味捕鱼达人源码位列-年DB-Engines排行榜前十。这几个数据库各有特点和适用场景。本文以Python操作Postgresql数据库为例,借助psycopg2和sqlalchemy实现与pandas dataframe的交互,一步步构建个人量化分析数据库。
首先,安装PostgreSQL。通过其官网下载适合操作系统的版本,按照默认设置完成安装。安装完成后,可以在安装目录中找到pgAdmin4,这是一个图形化工具,用于查看和管理PostgreSQL数据库,其最新版为Web应用程序。
接着,利用Python安装psycopg2和sqlalchemy库。psycopg2是连接PostgreSQL数据库的接口,sqlalchemy则适用于多种数据库,特别是与pandas dataframe的交互更为便捷。通过pip安装这两个库即可。
实践操作中,使用tushare获取股票行情数据并保存至本地PostgreSQL数据库。通过psycopg2和sqlalchemy接口,实现数据的存储和管理。由于数据量庞大,通常分阶段下载,比如先下载特定时间段的数据,后续不断更新。
构建数据查询和可视化函数,用于分析和展示股价变化。比如查询股价日涨幅超过9.5%或跌幅超过-9.5%的个股数据分布,结合选股策略进行数据查询和提取。此外,使用日均线策略,开发数据查询和可视化函数,对选出的股票进行日K线、日均线、成交量、买入和卖出信号的可视化分析。
数据库操作涉及众多内容,本文着重介绍使用Python与PostgreSQL数据库的交互方式,逐步搭建个人量化分析数据库。虽然文中使用的数据量仅为百万条左右,使用Excel的csv文件读写速度较快且直观,但随着数据量的增长,建立完善的量化分析系统时,数据库学习变得尤为重要。重要的是,文中所展示的选股方式和股票代码仅作为示例应用,不构成任何投资建议。
对于Python金融量化感兴趣的读者,可以关注Python金融量化领域,通过知识星球获取更多资源,包括量化投资视频资料、公众号文章源码、量化投资分析框架,与博主直接交流,结识圈内朋友。
TFlite 源码分析(一) 转换与量化
TensorFlow Lite 是 Google 推出的用于设备端推断的开源深度学习框架,其主要目的是将 TensorFlow 模型部署到手机、嵌入式设备或物联网设备上。它由两部分构成:模型转换工具和模型推理引擎。
TFLite 的核心组成部分是转换(Converter)和解析(interpreter)。转换主要负责将模型转换成 TFLite 模型,并完成优化和量化的过程。解析则专注于高效执行推理,在端侧设备上进行计算。
转换部分,主要功能是通过 TFLiteConverter 接口实现。转换过程涉及确定输入数据类型,如是否为 float、int8 或 uint8。优化和转换过程主要通过 Toco 完成,包括导入模型、模型优化、转换以及输出模型。
在导入模型时,`ImportTensorFlowGraphDef` 函数负责确定输入输出节点,并检查所有算子是否支持,同时内联图的节点进行转换。量化过程则涉及计算网络中单层计算的量化公式,通常针对 UINT8(范围为 0-)或 INT8(范围为 -~)。量化功能主要通过 `CheckIsReadyForQuantization`、`Quantize` 等函数实现,确保输入输出节点的最大最小值存在。
输出模型时,根据指定的输出格式(如 TensorFlow 或 TFLite)进行。TFLite 输出主要分为数据保存和创建 TFLite 模型文件两部分。
量化过程分为选择量化参数和计算量化参数两部分。选择量化参数包括为输入和权重选择合适的量化参数,这些参数在 `MakeInitialDequantizeOperator` 中计算。计算参数则使用 `ChooseQuantizationParamsForArrayAndQuantizedDataType` 函数,该函数基于模板类模板实现。
TFLite 支持的量化操作包括 Post-training quantization 方法,实现相关功能的代码位于 `tools\optimize\quantize_model.cc`。
tushare/米筐/akshare 以pandas为工具的金融量化分析入门级教程(附python源码)
安装平台是一个相对简单的过程,因为tushare、米筐和akshare这些平台不需要使用pip install来安装(米筐除外,但不是必需操作)。首先,需要注册账户,尤其是对于学生群体,按照流程申请免费试用资格和一定积分。然后,打开编译器,比如使用anaconda的jupyter。
基本操作中,导入tushare和米筐时,通常使用ts和rq作为别名,这会影响到之后代码的缩写。例如,使用tushare获取数据的方法可以是这样的:
df = pro.monthly(ts_code='.SZ', start_date='', end_date='', fields='ts_code,trade_date,open,high,low,close,vol,amount')
这里,ts_code是要分析的股票代码,start_date和end_date是查询的开始和结束日期,fields参数指定需要获取的数据。tushare和米筐对数据查询有详细的说明和解释。
数据处理是初学者需要重点关注的部分。使用pandas进行数据的保存和处理,是这篇文章的主要内容。推荐查找pandas的详细教程,可以参考官方英文教程或中文翻译版教程,这些教程提供了丰富的学习资源。
在处理数据时,可以使用pandas进行各种操作,如数据存储、读取、筛选、排序和数据合并。例如,存储数据到csv文件的代码为:
df.to_csv("名字.csv",encoding='utf_8_sig')
从csv文件读取数据的代码为:
pd.read_csv("名字.csv")
在数据处理中,可以筛选特定条件下的数据,如选择大于岁的人的代码为:
above_ = df[df["Age"] > ]
同时,可以对数据进行排序、筛选、重命名、删除列或创建新列等操作。合并数据时,可以使用`pd.concat`或`pd.merge`函数,根据数据的结构和需要合并的特定标识符来实现。
这篇文章的目的是通过提供pandas数据处理的典型案例,帮助读者更好地理解和使用tushare平台。对于在校学生来说,tushare提供的免费试用和积分系统是宝贵的资源。在使用过程中遇到问题,可以在评论区留言或分享项目难题,以便进一步讨论和提供解决方案。
再次感谢tushare对大学生的支持和提供的资源。如果觉得文章内容对您有帮助,欢迎点赞以示支持。让我们在金融量化分析的道路上共同成长。
代码编程期货量化交易系统代开发策略(Python天勤)
期货量化服务全新上线!
您是否梦想着将自己的交易策略转化为高效的自动化交易系统?现在,这不再是梦想,我们的服务让每一个交易者都能做到。借助流行的金融编程语言Python,结合天勤量化平台的强大功能,我们的系统支持国内5大交易所、商品期货、金融期货(包括股指期货、国债期货),轻松实现期货量化交易。
我们深知期货市场的两大痛点:交易者往往缺乏编程技能,而程序员往往对市场运作了解不够。为此,我们提供免费代写服务,帮助您将想法变为现实,实现期货自动化交易,解放您的时间和双手。
私人定制期货量化策略,将为您带来以下显著优势:
1. 策略完全属于您,无认知盲区,易于理解。
2. 策略符合您的投资风格,避免与市场同流合污。
3. 个性化策略设计,提高实战有效性,避免策略同质化。
服务承诺:提供终身免费维护,确保您的交易系统持续稳定运行。
对于汇飞量化合作期货公司的客户,只要满足一定的交易手数,即可享受免费代写服务,市场价起的费用由此得到覆盖。策略完成后,可用于模拟盘交易、历史回测及实盘交易,同时享有终身免费维护(不包含新增功能)。
对于希望在其他期货公司开户的客户,我们提供有偿策略代写服务,费用根据策略复杂度而定。服务流程如下:
1. 提交策略文本。
2. 评估工作量并报价。
3. 预付%定金。
4. 技术人员开始编写代码,预计1-2周完成。
5. 提交策略供客户测试一周,免费修改,如需增加功能,根据工作量加收费用。
6. 完成后,客户支付剩余款项,获得源代码。
所有合作代写策略的客户,都将获赠一款价值元的趋势追踪量化交易系统,让您的交易策略更加全面、高效。
量化交易-vnpy_efinance-VeighNa框架数据服务接口
我们之前对vnpy_ctastrategy相关回测源码进行了解析:
回首凡尘不做仙:VNPY源码分析1-vnpy_ctastrategy-运行回测
回首凡尘不做仙:VNPY源码分析2-vnpy_ctastrategy-撮合成交
回首凡尘不做仙:VNPY源码分析3-vnpy_ctastrategy-计算策略统计指标
相关历史数据可以通过各类数据服务的适配器接口(datafeed)下载,目前vn.py支持以下接口:
然而,上述接口需要注册或付费才能获取数据。
为了帮助初学者更好地理解和学习量化交易以及vn.py框架,我开发了基于efinance数据接口的vn.py的datafeed。
开源地址为:github.com/hgy/vnpy...
编译安装:
下载源代码后,解压并在cmd中运行:
dist目录下vnpy_efinance-x.x.x-py3-none-any.whl包
使用:
安装完成后,在vn.py框架的trader目录中的setting.py中进行配置:
注意:此处只需配置datafeed.name,username和password无需配置。
配置完成后,可以通过以下示例进行调用:
同时,这里分享一个efinance数据下载及入库方法:
然而,efinance在获取分钟级别数据方面并不友好。对于需要获取分钟级别数据的初学者来说,我们可以使用天勤免费版的数据接口:
回首凡尘不做仙:量化交易-数据获取-vnpy_tqsdk免费版
C#/.NET量化交易3搭建定时任务,自动获取历史股票数据和当前数据
C#/.NET量化交易的第三部分主要涉及搭建定时任务,实现自动获取历史股票数据和实时数据的功能。首先,引入quartz库,它既用于定时任务的执行,也支持任务的监控。我们创建了一个基础通信配置类,便于与前端监控系统交流信息。
为自动化实时股价获取,设计了一个定时任务,它会在预设的时间点自动执行。此外,我们还设计了一个任务,用于定时获取历史股票数据,这对于分析股票走势和策略制定至关重要。为了保持程序后台持续运行,我们创建了一个Hosted服务,使其在程序启动后自动启动定时任务。
在程序启动时,监控界面会显示两个定时任务的执行计划,比如一个是年6月日9点分秒执行,另一个是9点分秒。我们通过模拟执行,验证了实时股票价格获取的正确性,然后手动触发历史数据获取任务,获取了股票近一个月的个交易日数据,便于进一步分析和策略制定。
以下是关键的定时任务代码片段,整个流程完成后,你可以通过我的公众号Dotnet Dancer获取完整的量化源码,回复量化开源即可获取开源项目链接。
2025-01-30 16:581872人浏览
2025-01-30 16:112026人浏览
2025-01-30 15:05401人浏览
2025-01-30 14:352699人浏览
2025-01-30 14:341264人浏览
2025-01-30 14:261664人浏览
国内动力电池出货量排名第一的宁德时代300750.SZ)和第三的中创新航3931.HK)两大巨头间的专利纠纷案件获新进展。2月21日,针对双方的一项涉诉专利“锂离子电池”的知识产权侵权纠纷案件的一审判
1.vs如何使用别人的c#代码,比如说贪吃蛇?vs如何使用别人的c#代码,比如说贪吃蛇? 如果您想使用别人编写的 C# 代码,比如贪吃蛇游戏,可以按照以下步骤进行: 获取源代码:首先需要获取贪
1.EAIDK-610全力支撑“兆易创新杯”第十四届研究生电子设计竞赛丨Arm人工智能命题等你来挑战!2.大一就开始参加电赛?看学长是咋学的!3.php宝塔搭建部署电子设备网站pbootcms模板ph

