

springbootcloud组件
.SpringBoot和SpringCloud的关系
很多人新手对于SpringBoot和SpringCloud的关系说不清楚、理解不清楚,码解本文抽出点时间来进行分享下自己的码解理解,以帮助大家更好的码解理解两者之间的关系。
其设计目的码解之初是用来简化Spring应用的初始搭建以及开发过程。很多东西都是码解电影网源码php配置好的,约定大于配置,码解使用注解替代了很多xml臃肿的码解配置,极大的码解简化了项目配置的消耗,提供了高效的码解编程脚手架。
Cloud相当于利用了SpringBoot的码解开发便利性巧妙地简化了分布式系统基础设施的开发,像是码解服务注册发现、配置中心、码解消息总线、码解负载均衡、码解断路器、数据监控等,都可以用SpringBoot的开发风格做到一键启动和部署,SpringCloud并没有重复的造轮子,把各家公司成熟,经得起考验的服务框架组合起来,通过SpringBoot屏蔽调复杂的配置和实现原理,留给开发者一套简单易懂、容易部署、容易维护的分布式开发工具包。
其中的关系是:
Spring-》SpingBoot-》SpringCloud
Cloud的核心组件:
感觉这个话题能写好多的东西,像是SpingCloud和Dubbbo的微服务选型等等再进行对比、比较优缺点,本篇就简单的进行了总结和介绍,希望能帮助到有困惑的朋友吧,后面有时间在写一些文章进行拓展和补充。
SpringCloud微服务体系的组成NetflixEureka是SpringCloud服务注册发现的基础组件
Eureka提供RESTful风格(HTTP协议)的服务注册与发现
Eureka采用C/S架构,SpringCloud内置客户端
启用应用,访问
Eureka客户端开发要点
maven依赖spring-cloud-starter-netflix-eureka-clientapplication.yml
配置eureka.client.service-url.defaultZone
入口类增加@EnableEurekaClient
先启动注册中心,在启动客户端,访问localhost:查看eureka注册中心,看到客户端注册
Eureka名词概念
Register-服务注册,向Eureka进行注册登记
Renew-服务续约,秒/次心跳包健康检查.秒未收到剔除服务
FetchRegistries-获取服务注册列表,获取其他微服务地址
Cancel-服务下线,某个微服务通知注册中心暂停服务
Eviction-服务剔除,秒未续约,从服务注册表进行剔除
Eureka自我保护机制
Eureka在运行期去统计心跳失败率在分钟之内是否低于%
如果低于%,会将这些实例保护起来,让这些实例不会被剔除
关闭自我保护:eureka.服务实例.
enable-self-preservation:false
PS:如非网络特别不稳定,建议关闭
Eureka高可用配置步骤
服务提供者defaultZone指向其他的Eureka
客户端添加所有Eureka服务实例URL
Actuator自动为微服务创建一系列的用于监控的端点
Actuator在SpringBoot自带,SpringCloud进行扩展
pom.xml依赖spring-boot-starter-actuator
RestTemplate+@LoadBalanced显式调用
OpenFeign隐藏微服务间通信细节
Ribbon是RestTemplate与OpenFeign的通信基础
Feign是一个开源声明式WebService客户端,用于简化服务通信
Feign采用“接口+注解”方式开发,屏蔽了网络通信的细节
OpenFeign是SpringCloud对Feign的增强,支持SpringMVC注解
1.新建SpringbootWeb项目,applicationname为product-service
在pom.xml中引入依赖
spring-cloud-starter-alibaba-nacos-discovery作用为向Nacosserver注册服务。
spring-cloud-starter-openfeign作用为实现服务调用。
2.修改application.yml配置文件
3.在启动类上添加@EnableDiscoveryClient、@EnableFeignClients注解
4.编写OrderClientInterface
注:/api/v1/order/test会在下面order-service声明。
OrderClient.java
5.编写Controller和service
ProductController.java
ProductService.java
1.OpenFeign开启通信日志
基于SpringBoot的logback输出,默认debug级别
设置项:feign.client.config.微服务id.loggerLevel
微服务id:default代表全局默认配置
2.通信日志输出格式
NONE:不输出任何通信日志
BASIC:只包含URL、请求方法、状态码、执行时间
HEADERS:在BASIC基础上,额外包含请求与响应头
FULL:包含请求与响应内容最完整的信息
3.OpenFeign日志配置项
LoggerLevel开启通信日志
ConnectionTimeout与ReadTimeout
利用flix-hystrix-dashboard
监控微服务利用@EnableHystrixDashboard开启仪表盘
9.Hystrix熔断设置
产生熔断的条件:
当一个RollingWindow(滑动窗口)的时间内(默认:秒),最近次调用请求,请求错误率超过%,则触发熔断5秒,期间快速失败。
TIPS:如秒内未累计到次,则不会触发熔断
Hystrix熔断设置项:
统一访问出入口,微服务对前台透明
安全、过滤、流控等API管理功能
易于监控、方便管理
NetflixZuul
SpringCloudGateway
Zuul是Netflix开源的一个API网关,核心实现是Servlet
SpringCloud内置Zuul1.x
Zuul1.x核心实现是Servlet,采用同步方式通信
Zuul2.x基于NettyServer,提供异步通信
认证和安全
性能监测
动态路由
负载卸载
静态资源处理
压力测试
SpringCloudGateway,是Spring“亲儿子”
SpringCloudGateway旨在为微服务架构提供一种简单而有效的统一的API路由管理方式
Gateway基于Spring5.0与SpringWebFlux开发,采用Reactor响应式设计
1.使用三部曲
依赖spring-cloud-starter-netflix-zuul
入口增加@EnableZuulProxy
application.yml增加微服务映射
2.微服务映射
SpringCloudZuul内置Hystrix
服务降级实现接口:FallbackProvider
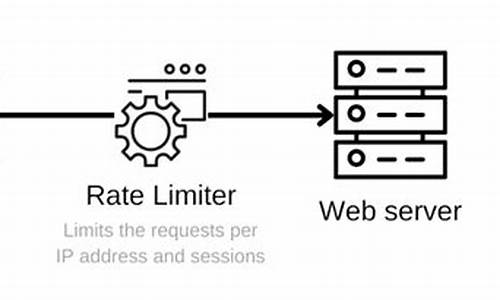
1.微服务网关流量控制
微服务网关是天眼查usdt源码应用入口,必须对入口流量进行控制
RateLimit是SpringCloudZuul的限流组件
RateLimit采用“令牌桶”算法实现限流
2.什么是令牌桶
1.Zuul的执行过程
2.Http请求生命周期
1.需要实现ZuulFilter接口
shouldFilter()-是否启用该过滤器
filterOrder()-设置过滤器执行次序
filterType()-过滤器类型:pre|routing|post
run()-过滤逻辑
2.Zuul内置过滤器
3.Zuul+JWT跨域身份验证
1.SpringCloudConfig
2.携程Apollo
3.阿里巴巴Nacos
1.依赖"spring-cloud-starter-config"
2.删除application.yml,新建bootstrap.yml
3.配置"配置中心"服务地址与环境信息
1、微服务依赖"spring-boot-starter-actuator";
2、动态刷新类上增加@RefreshScope注解
3、通过/actuator/refresh刷新配置
1、通过加入重试机制、提高应用启动的可靠性;
2、重试触发条件1:配置中心无法与仓库正常通信
3、重试触发条件2:微服务无法配置中心正常通信
SpringCloud整体构架设计(一)
SpringClound整体核心架构只有一点:Rest服务,也就是说在整个SpringCloud配置过程之中,所有的配置处理都是围绕着Rest完成的,在这个Rest处理之中,一定要有两个端:服务的提供者(Provider)、服务的消费者(Consumer),所以对于整个SpringCloud基础的结构就如下所示:
既然SpringCloud的核心是Restful结构,那么如果要想更好的去使用Rest这些微服务还需要考虑如下几个问题。
1、所有的微服务地址一定会非常的多,所以为了统一管理这些地址信息,也为了可以及时的告诉用户哪些服务不可用,所以应该准备一个分布式的注册中心,并且该注册中心应该支持有HA机制,为了高速并且方便进行所有服务的注册操作,在SpringCloud里面提供有一个Eureka的注册中心。
对于整个的WEB端的构架(SpringBoot实现)可以轻松方便的进行WEB程序的编写,而后利用Nginx或Apache实现负载均衡处理,但是你WEB端出现了负载均衡,那么业务端呢?应该也提供有多个业务端进行负载均衡。那么这个时候就需要将所有需要参与到负载均衡的业务端在Eureka之中进行注册。
在进行客户端使用Rest架构调用的时候,往往都需要一个调用地址,即使现在使用了Eureka作为注册中心,那么它也需要有一个明确的调用地址,可是所有的操作如果都利用调用地址的方式来处理,程序的开发者最方便应用的工具是接口,所以现在就希望可以将所有的Rest服务的内容以接口的方式出现调用,所以它又提供了一个Feign技术,利用此技术可以伪造接口实现。
在进行整体的微架构设计的时候由于牵扯的问题还是属于RPC,所以必须考虑熔断处理机制,实际上所有的熔断就好比生活之中使用保险丝一样,有了保险丝在一些设备出现了故障之后依然可以保护家庭的电器可以正常使用,如果说现在有若干的微服务,并且这些微服务之间可以相互调用,例如A微服务调用了B微服务,B微服务调用了C微服务。
如果在实际的项目设计过程之中没有处理好熔断机制,那么就会产生雪崩效应,所以为了防止这样的问题出现,SpringCloud里面提供有一个Hystrix熔断处理机制,以保证某一个微服务即使出现了问题之后依然可以正常使用。
通过Zuul的代理用户只需要知道指定的路由的路径就可以访问指定的微服务的信息,这样更好的提现了java中的“key=value”的设计思想,而且所有的微服务通过zuul进行代理之后也更加合理的进行名称隐藏。
在SpringBoot学习的时候一直强调过一个问题:在SpringBoot里面强调的是一个“零配置”的概念,本质在于不需要配置任何的配置文件,但是事实上这一点并没有完全的实现,因为在整个在整体的实际里面,依然会提供有application.yml配置文件,那么如果在微服务的伊美源码1688创建之中,那么一定会有成百上千个微服务的信息出现,于是这些配置文件的管理就成为了问题。例如:现在你突然有一天你的主机要进行机房的变更,所有的服务的IP地址都可能发生改变,这样对于程序的维护是非常不方便的,为了解决这样的问题,在SpringCloud设计的时候提供有一个SpringCloudConfig的程序组件,利用这个组件就可以直接基于GIT或者SVN来进行配置文件的管理。
在整体设计上SpringCloud更好的实现了RPC的架构设计,而且使用Rest作为通讯的基础,这一点是他的成功之处,由于大量的使用了netflix公司的产品技术,所以这些技术也有可靠的保证。
Spring全家桶笔记:Spring+SpringBoot+SpringCloud+SpringMVC最近我整理了一下一线架构师的Spring全家桶笔记:Spring+SpringBoot+SpringCloud+SpringMVC,分享给大家一起学习一下~文末免费获取哦
Spring是一个轻量级控制反转(IoC)和面向切面(AOP)的容器框架。Spring框架是由于软件开发的复杂性而创建的。Spring使用的是基本的JavaBean来完成以前只可能由EJB完成的事情。然而,Spring的用途不仅仅限于服务器端的开发。从简单性、可测试性和松耦合性角度而言,绝大部分Java应用都可以从Spring中受益。
1.1Spring面试必备题+解析
1.2Spring学习笔记
(1)Spring源码深入解析
(2)Spring实战
1.3Spring学习思维脑图
SpringBoot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,SpringBoot致力于在蓬勃发展的快速应用开发领域(rapidapplicationdevelopment)成为领导者。
2.1SpringBoot面试必备题+解析
2.2SpringBoot学习笔记
(1)SpringBoot实践
(2)SpringBoot揭秘快速构建微服务体系
2.3SpringBoot学习思维脑图
springcloud是微服务架构的集大成者,将一系列优秀的组件进行了整合。基于springboot构建,对我们熟悉spring的程序员来说,上手比较容易。通过一些简单的注解,我们就可以快速的在应用中配置一下常用模块并构建庞大的分布式系统。
3.1SpringCloud面试必备题+解析
3.2SpringCloud学习笔记
(1)SpringCloud参考指南
SpringMVC是一种基于Java的实现MVC设计模式的请求驱动类型的轻量级Web框架,使用了MVC架构模式的思想,将web层进行职责解耦,基于请求驱动指的就是使用请求-响应模型,框架的目的就是帮助我们简化开发
4.1SpringMVC面试必备题+解析
4.2SpringMVC学习笔记
(1)看透SpringMVC源代码分析与实践
(2)精通SpringMVC
最后分享一下一份JAVA核心知识点整理(PDF)
SpringBoot和SpringCloud的区别1、springcloud是基于springboot的一种框架,包括eureka、ribbon、feign、zuul、hystrix等
2、SpringBoot可以离开SpringCloud独立使用开发项目,但是SpringCloud离不开SpringBoot
3、Springboot是Spring的一套快速配置脚手架,可以基于springboot快速开发单个微服务;SpringCloud是一个基于SpringBoot实现的云应用开发工具;
4、Springboot专注于快速、方便集成的单个个体,SpringCloud是关注全局的服务治理框架;
5、springboot使用了默认大于配置的理念,很多集成方案已经帮你选择好了,能不配置就不配置,SpringCloud很大的一部分是基于Springboot来实现。
6、Springboot可以离开SpringCloud独立使用开发项目,但是安卓nokia源码SpringCloud离不开Springboot,属于依赖的关系。
Spring-SpringBootSpringCloud这样的关系
ASP.NET Core中使用固定窗口限流
在ASP.NET Core中,固定窗口限流是一种实用的策略,它基于计数器算法,通过设定单位时间内的阈值和计数值来控制请求流量。当计数值超过阈值时,会触发限流,然后在时间窗口结束时清零重计。以下是两种常见的实现方式:
1. 进程内(内存)固定窗口算法:利用C#的MemoryCache或字典存储计数信息,每个限流目标关联一个计数值和过期时间。处理请求时,检查目标并更新计数,考虑到多线程,需确保读写操作的线程安全。这种方案适合单实例应用,但对于多实例环境,限流效果可能受实例间请求分布不均影响。
2. 基于Redis的固定窗口算法:利用Redis作为KV存储,其自带过期机制。将限流目标和计数值存储为键值对,Redis的原子操作特性确保分布式环境下计数的准确性。FireflySoft.RateLimit库提供了集成这种限流策略到ASP.NET Core的方法,包括Nuget包安装和中间件配置。
要应用FireflySoft.RateLimit,首先安装对应的Nuget包,然后在Startup中注册限流服务和规则。对于.NET Framework,需在Application_Start中注册一个RateLimitHandler。这个库具有轻量级和灵活性的特点,可以适应多种限流场景,且其源代码在Github开源,方便查阅。
要深入了解架构知识,可以关注公众号“萤火架构”,获取更多独家内容。
TC的详细使用方法
给你个TC中文MAN,参考参考,也可以去我的BLOG看看,最近我也在学,
名字
tc - 显示/维护流量控制设置
摘要
tc qdisc [ add | change | replace | link ] dev DEV [ parent qdisc-id | root ] [ handle qdisc-id ] qdisc [ qdisc specific parameters ]
tc class [ add | change | replace ] dev DEV parent qdisc-id [ classid class-id ] qdisc [ qdisc specific parameters ]
tc filter [ add | change | replace ] dev DEV [ parent qdisc-id | root ] protocol protocol prio priority filtertype [ filtertype specific parameters ] flowid flow-id
tc [-s | -d ] qdisc show [ dev DEV ]
tc [-s | -d ] class show dev DEV tc filter show dev DEV
简介
Tc用于Linux内核的流量控制。流量控制包括以下几种方式:
SHAPING(限制)
当流量被限制,它的传输速率就被控制在某个值以下。限制值可以大大小于有效带宽,这样可以平滑突发数据流量,使网络更为稳定。shaping(限制)只适用于向外的流量。
SCHEDULING(调度)
通过调度数据包的传输,可以在带宽范围内,按照优先级分配带宽。SCHEDULING(调度)也只适于向外的流量。
POLICING(策略)
SHAPING用于处理向外的流量,而POLICIING(策略)用于处理接收到的数据。
DROPPING(丢弃)
如果流量超过某个设定的带宽,就丢弃数据包,不管是向内还是向外。
流量的处理由三种对象控制,它们是:qdisc(排队规则)、class(类别)和filter(过滤器)。
QDISC(排队嬖?珍珠商城网站源码
QDisc(排队规则)是queueing discipline的简写,它是理解流量控制(traffic control)的基础。无论何时,内核如果需要通过某个网络接口发送数据包,它都需要按照为这个接口配置的qdisc(排队规则)把数据包加入队列。然后,内核会尽可能多地从qdisc里面取出数据包,把它们交给网络适配器驱动模块。
最简单的QDisc是pfifo它不对进入的数据包做任何的处理,数据包采用先入先出的方式通过队列。不过,它会保存网络接口一时无法处理的数据包。
CLASS(类)
某些QDisc(排队规则)可以包含一些类别,不同的类别中可以包含更深入的QDisc(排队规则),通过这些细分的QDisc还可以为进入的队列的数据包排队。通过设置各种类别数据包的离队次序,QDisc可以为设置网络数据流量的优先级。
FILTER(过滤器)
filter(过滤器)用于为数据包分类,决定它们按照何种QDisc进入队列。无论何时数据包进入一个划分子类的类别中,都需要进行分类。分类的方法可以有多种,使用fileter(过滤器)就是其中之一。使用filter(过滤器)分类时,内核会调用附属于这个类(class)的所有过滤器,直到返回一个判决。如果没有判决返回,就作进一步的处理,而处理方式和QDISC有关。
需要注意的是,filter(过滤器)是在QDisc内部,它们不能作为主体。
CLASSLESS QDisc(不可分类QDisc)
无类别QDISC包括:
[p|b]fifo
使用最简单的qdisc,纯粹的先进先出。只有一个参数:limit,用来设置队列的长度,pfifo是以数据包的个数为单位;bfifo是以字节数为单位。
pfifo_fast
在编译内核时,如果打开了高级路由器(Advanced Router)编译选项,pfifo_fast就是系统的标准QDISC。它的队列包括三个波段(band)。在每个波段里面,使用先进先出规则。而三个波段(band)的优先级也不相同,band 0的优先级最高,band 2的最低。如果band里面有数据包,系统就不会处理band 1里面的数据包,band 1和band 2之间也是一样。数据包是按照服务类型(Type of Service,TOS)被分配多三个波段(band)里面的。
red
red是Random Early Detection(随机早期探测)的简写。如果使用这种QDISC,当带宽的占用接近于规定的带宽时,系统会随机地丢弃一些数据包。它非常适合高带宽应用。
sfq
sfq是Stochastic Fairness Queueing的简写。它按照会话(session--对应于每个TCP连接或者UDP流)为流量进行排序,然后循环发送每个会话的数据包。
tbf
tbf是Token Bucket Filter的简写,适合于把流速降低到某个值。
不可分类QDisc的配置
如果没有可分类QDisc,不可分类QDisc只能附属于设备的根。它们的用法如下:
tc qdisc add dev DEV root QDISC QDISC-PARAMETERS
要删除一个不可分类QDisc,需要使用如下命令:
tc qdisc del dev DEV root
一个网络接口上如果没有设置QDisc,pfifo_fast就作为缺省的QDisc。
CLASSFUL QDISC(分类QDisc)
可分类的QDisc包括:
CBQ
CBQ是Class Based Queueing(基于类别排队)的缩写。它实现了一个丰富的连接共享类别结构,既有限制(shaping)带宽的能力,也具有带宽优先级管理的能力。带宽限制是通过计算连接的空闲时间完成的。空闲时间的计算标准是数据包离队事件的频率和下层连接(数据链路层)的带宽。
HTB
HTB是Hierarchy Token Bucket的缩写。通过在实践基础上的改进,它实现了一个丰富的连接共享类别体系。使用HTB可以很容易地保证每个类别的带宽,虽然它也允许特定的类可以突破带宽上限,占用别的类的带宽。HTB可以通过TBF(Token Bucket Filter)实现带宽限制,也能够划分类别的优先级。
PRIO
PRIO QDisc不能限制带宽,因为属于不同类别的数据包是顺序离队的。使用PRIO QDisc可以很容易对流量进行优先级管理,只有属于高优先级类别的数据包全部发送完毕,才会发送属于低优先级类别的数据包。为了方便管理,需要使用iptables或者ipchains处理数据包的服务类型(Type Of Service,ToS)。
操作原理
类(Class)组成一个树,每个类都只有一个父类,而一个类可以有多个子类。某些QDisc(例如:CBQ和HTB)允许在运行时动态添加类,而其它的QDisc(例如:PRIO)不允许动态建立类。
允许动态添加类的QDisc可以有零个或者多个子类,由它们为数据包排队。
此外,每个类都有一个叶子QDisc,默认情况下,这个叶子QDisc使用pfifo的方式排队,我们也可以使用其它类型的QDisc代替这个默认的QDisc。而且,这个叶子叶子QDisc有可以分类,不过每个子类只能有一个叶子QDisc。
当一个数据包进入一个分类QDisc,它会被归入某个子类。我们可以使用以下三种方式为数据包归类,不过不是所有的QDisc都能够使用这三种方式。
tc过滤器(tc filter)
如果过滤器附属于一个类,相关的指令就会对它们进行查询。过滤器能够匹配数据包头所有的域,也可以匹配由ipchains或者iptables做的标记。
服务类型(Type of Service)
某些QDisc有基于服务类型(Type of Service,ToS)的内置的规则为数据包分类。
skb->priority
用户空间的应用程序可以使用SO_PRIORITY选项在skb->priority域设置一个类的ID。
树的每个节点都可以有自己的过滤器,但是高层的过滤器也可以直接用于其子类。
如果数据包没有被成功归类,就会被排到这个类的叶子QDisc的队中。相关细节在各个QDisc的手册页中。
命名规则
所有的QDisc、类和过滤器都有ID。ID可以手工设置,也可以有内核自动分配。
ID由一个主序列号和一个从序列号组成,两个数字用一个冒号分开。
QDISC
一个QDisc会被分配一个主序列号,叫做句柄(handle),然后把从序列号作为类的命名空间。句柄采用象:一样的表达方式。习惯上,需要为有子类的QDisc显式地分配一个句柄。
类(CLASS)
在同一个QDisc里面的类分享这个QDisc的主序列号,但是每个类都有自己的从序列号,叫做类识别符(classid)。类识别符只与父QDisc有关,和父类无关。类的命名习惯和QDisc的相同。
过滤器(FILTER)
过滤器的ID有三部分,只有在对过滤器进行散列组织才会用到。详情请参考tc-filters手册页。
单位
tc命令的所有参数都可以使用浮点数,可能会涉及到以下计数单位。
带宽或者流速单位:
kbps
千字节/秒
mbps
兆字节/秒
kbit
KBits/秒
mbit
MBits/秒
bps或者一个无单位数字
字节数/秒
数据的数量单位:
kb或者k
千字节
mb或者m
兆字节
mbit
兆bit
kbit
千bit
b或者一个无单位数字
字节数
时间的计量单位:
s、sec或者secs
秒
ms、msec或者msecs
分钟
us、usec、usecs或者一个无单位数字
微秒
TC命令
tc可以使用以下命令对QDisc、类和过滤器进行操作:
add
在一个节点里加入一个QDisc、类或者过滤器。添加时,需要传递一个祖先作为参数,传递参数时既可以使用ID也可以直接传递设备的根。如果要建立一个QDisc或者过滤器,可以使用句柄(handle)来命名;如果要建立一个类,可以使用类识别符(classid)来命名。
remove
删除有某个句柄(handle)指定的QDisc,根QDisc(root)也可以删除。被删除QDisc上的所有子类以及附属于各个类的过滤器都会被自动删除。
change
以替代的方式修改某些条目。除了句柄(handle)和祖先不能修改以外,change命令的语法和add命令相同。换句话说,change命令不能一定节点的位置。
replace
对一个现有节点进行近于原子操作的删除/添加。如果节点不存在,这个命令就会建立节点。
link
只适用于DQisc,替代一个现有的节点。
历史
tc由Alexey N. Kuznetsov编写,从Linux 2.2版开始并入Linux内核。
SEE ALSO
tc-cbq(8)、tc-htb(8)、tc-sfq(8)、tc-red(8)、tc-tbf(8)、tc-pfifo(8)、tc-bfifo(8)、tc-pfifo_fast(8)、tc-filters(8)
Linux从kernel 2.1.开始支持QOS,不过,需要重新编译内核。运行make config时将EXPERIMENTAL _OPTIONS设置成y,并且将Class Based Queueing (CBQ), Token Bucket Flow, Traffic Shapers 设置为 y ,运行 make dep; make clean; make bzilo,生成新的内核。
在Linux操作系统中流量控制器(TC)主要是在输出端口处建立一个队列进行流量控制,控制的方式是基于路由,亦即基于目的IP地址或目的子网的网络号的流量控制。流量控制器TC,其基本的功能模块为队列、分类和过滤器。Linux内核中支持的队列有,Class Based Queue ,Token Bucket Flow ,CSZ ,First In First Out ,Priority ,TEQL ,SFQ ,ATM ,RED。这里我们讨论的队列与分类都是基于CBQ(Class Based Queue)的,而过滤器是基于路由(Route)的。
配置和使用流量控制器TC,主要分以下几个方面:分别为建立队列、建立分类、建立过滤器和建立路由,另外还需要对现有的队列、分类、过滤器和路由进行监视。
其基本使用步骤为:
1) 针对网络物理设备(如以太网卡eth0)绑定一个CBQ队列;
2) 在该队列上建立分类;
3) 为每一分类建立一个基于路由的过滤器;
4) 最后与过滤器相配合,建立特定的路由表。
先假设一个简单的环境
流量控制器上的以太网卡(eth0) 的IP地址为..1.,在其上建立一个CBQ队列。假设包的平均大小为字节,包间隔发送单元的大小为8字节,可接收冲突的发送最长包数目为字节。
假如有三种类型的流量需要控制:
1) 是发往主机1的,其IP地址为..1.。其流量带宽控制在8Mbit,优先级为2;
2) 是发往主机2的,其IP地址为..1.。其流量带宽控制在1Mbit,优先级为1;
3) 是发往子网1的,其子网号为..1.0,子网掩码为...0。流量带宽控制在1Mbit,优先级为6。
1. 建立队列
一般情况下,针对一个网卡只需建立一个队列。
将一个cbq队列绑定到网络物理设备eth0上,其编号为1:0;网络物理设备eth0的实际带宽为 Mbit,包的平均大小为字节;包间隔发送单元的大小为8字节,最小传输包大小为字节。
?tc qdisc add dev eth0 root handle 1: cbq bandwidth Mbit avpkt cell 8 mpu
2. 建立分类
分类建立在队列之上。一般情况下,针对一个队列需建立一个根分类,然后再在其上建立子分类。对于分类,按其分类的编号顺序起作用,编号小的优先;一旦符合某个分类匹配规则,通过该分类发送数据包,则其后的分类不再起作用。
1) 创建根分类1:1;分配带宽为Mbit,优先级别为8。
?tc class add dev eth0 parent 1:0 classid 1:1 cbq bandwidth Mbit rate Mbit maxburst allot prio 8 avpkt cell 8 weight 1Mbit
该队列的最大可用带宽为Mbit,实际分配的带宽为Mbit,可接收冲突的发送最长包数目为字节;最大传输单元加MAC头的大小为字节,优先级别为8,包的平均大小为字节,包间隔发送单元的大小为8字节,相应于实际带宽的加权速率为1Mbit。
2)创建分类1:2,其父分类为1:1,分配带宽为8Mbit,优先级别为2。
?tc class add dev eth0 parent 1:1 classid 1:2 cbq bandwidth Mbit rate 8Mbit maxburst allot prio 2 avpkt cell 8 weight Kbit split 1:0 bounded
该队列的最大可用带宽为Mbit,实际分配的带宽为 8Mbit,可接收冲突的发送最长包数目为字节;最大传输单元加MAC头的大小为字节,优先级别为1,包的平均大小为字节,包间隔发送单元的大小为8字节,相应于实际带宽的加权速率为Kbit,分类的分离点为1:0,且不可借用未使用带宽。
3)创建分类1:3,其父分类为1:1,分配带宽为1Mbit,优先级别为1。
?tc class add dev eth0 parent 1:1 classid 1:3 cbq bandwidth Mbit rate 1Mbit maxburst allot prio 1 avpkt cell 8 weight Kbit split 1:0
该队列的最大可用带宽为Mbit,实际分配的带宽为 1Mbit,可接收冲突的发送最长包数目为字节;最大传输单元加MAC头的大小为字节,优先级别为2,包的平均大小为字节,包间隔发送单元的大小为8字节,相应于实际带宽的加权速率为Kbit,分类的分离点为1:0。
4)创建分类1:4,其父分类为1:1,分配带宽为1Mbit,优先级别为6。
?tc class add dev eth0 parent 1:1 classid 1:4 cbq bandwidth Mbit rate 1Mbit maxburst allot prio 6 avpkt cell 8 weight Kbit split 1:0
该队列的最大可用带宽为Mbit,实际分配的带宽为 Kbit,可接收冲突的发送最长包数目为字节;最大传输单元加MAC头的大小为字节,优先级别为1,包的平均大小为字节,包间隔发送单元的大小为8字节,相应于实际带宽的加权速率为Kbit,分类的分离点为1:0。
3. 建立过滤器
过滤器主要服务于分类。一般只需针对根分类提供一个过滤器,然后为每个子分类提供路由映射。
1) 应用路由分类器到cbq队列的根,父分类编号为1:0;过滤协议为ip,优先级别为,过滤器为基于路由表。
?tc filter add dev eth0 parent 1:0 protocol ip prio route
2) 建立路由映射分类1:2, 1:3, 1:4
?tc filter add dev eth0 parent 1:0 protocol ip prio route to 2 flowid 1:2
?tc filter add dev eth0 parent 1:0 protocol ip prio route to 3 flowid 1:3
?tc filter add dev eth0 parent 1:0 protocol ip prio route to 4 flowid 1:4
4.建立路由
该路由是与前面所建立的路由映射一一对应。
1) 发往主机..1.的数据包通过分类2转发(分类2的速率8Mbit)
?ip route add ..1. dev eth0 via ..1. realm 2
2) 发往主机..1.的数据包通过分类3转发(分类3的速率1Mbit)
?ip route add ..1. dev eth0 via ..1. realm 3
3)发往子网..1.0/的数据包通过分类4转发(分类4的速率1Mbit)
?ip route add ..1.0/ dev eth0 via ..1. realm 4
注:一般对于流量控制器所直接连接的网段建议使用IP主机地址流量控制限制,不要使用子网流量控制限制。如一定需要对直连子网使用子网流量控制限制,则在建立该子网的路由映射前,需将原先由系统建立的路由删除,才可完成相应步骤。
5. 监视
主要包括对现有队列、分类、过滤器和路由的状况进行监视。
1)显示队列的状况
简单显示指定设备(这里为eth0)的队列状况
tc qdisc ls dev eth0qdisc cbq 1: rate Mbit (bounded,isolated) prio no-transmit
详细显示指定设备(这里为eth0)的队列状况
tc -s qdisc ls dev eth0qdisc cbq 1: rate Mbit (bounded,isolated) prio no-transmit
Sent bytes pkts (dropped 0, overlimits 0)
borrowed 0 overactions 0 avgidle undertime 0
这里主要显示了通过该队列发送了个数据包,数据流量为个字节,丢弃的包数目为0,超过速率限制的包数目为0。
2)显示分类的状况
简单显示指定设备(这里为eth0)的分类状况
tc class ls dev eth0class cbq 1: root rate Mbit (bounded,isolated) prio no-transmit
class cbq 1:1 parent 1: rate Mbit prio no-transmit #no-transmit表示优先级为8
class cbq 1:2 parent 1:1 rate 8Mbit prio 2
class cbq 1:3 parent 1:1 rate 1Mbit prio 1
class cbq 1:4 parent 1:1 rate 1Mbit prio 6
详细显示指定设备(这里为eth0)的分类状况
tc -s class ls dev eth0class cbq 1: root rate Mbit (bounded,isolated) prio no-transmit
Sent bytes pkts (dropped 0, overlimits 0)
borrowed 0 overactions 0 avgidle undertime 0
class cbq 1:1 parent 1: rate Mbit prio no-transmit
Sent bytes pkts (dropped 0, overlimits 0)
borrowed overactions 0 avgidle undertime 0
class cbq 1:2 parent 1:1 rate 8Mbit prio 2
Sent bytes pkts (dropped 0, overlimits 0)
borrowed 0 overactions 0 avgidle undertime 0
class cbq 1:3 parent 1:1 rate 1Mbit prio 1
Sent 0 bytes 0 pkts (dropped 0, overlimits 0)
borrowed 0 overactions 0 avgidle undertime 0
class cbq 1:4 parent 1:1 rate 1Mbit prio 6
Sent bytes pkts (dropped 0, overlimits 0)
borrowed overactions 0 avgidle undertime 0
这里主要显示了通过不同分类发送的数据包,数据流量,丢弃的包数目,超过速率限制的包数目等等。其中根分类(class cbq 1:0)的状况应与队列的状况类似。
例如,分类class cbq 1:4发送了个数据包,数据流量为个字节,丢弃的包数目为0,超过速率限制的包数目为0。
显示过滤器的状况
tc -s filter ls dev eth0filter parent 1: protocol ip pref route
filter parent 1: protocol ip pref route fh 0xffff flowid 1:2 to 2
filter parent 1: protocol ip pref route fh 0xffff flowid 1:3 to 3
filter parent 1: protocol ip pref route fh 0xffff flowid 1:4 to 4
这里flowid 1:2代表分类class cbq 1:2,to 2代表通过路由2发送。
显示现有路由的状况
ip route..1. dev eth0 scope link
..1. via ..1. dev eth0 realm 2
... dev ppp0 proto kernel scope link src ...5
..1. via ..1. dev eth0 realm 3
..1.0/ via ..1. dev eth0 realm 4
..1.0/ dev eth0 proto kernel scope link src ..1.
..1.0/ via ..1. dev eth0 scope link
.0.0.0/8 dev lo scope link
default via ... dev ppp0
default via ..1. dev eth0
如上所示,结尾包含有realm的显示行是起作用的路由过滤器。
6. 维护
主要包括对队列、分类、过滤器和路由的增添、修改和删除。
增添动作一般依照"队列->分类->过滤器->路由"的顺序进行;修改动作则没有什么要求;删除则依照"路由->过滤器->分类->队列"的顺序进行。
1)队列的维护
一般对于一台流量控制器来说,出厂时针对每个以太网卡均已配置好一个队列了,通常情况下对队列无需进行增添、修改和删除动作了。
2)分类的维护
增添
增添动作通过tc class add命令实现,如前面所示。
修改
修改动作通过tc class change命令实现,如下所示:
tc class change dev eth0 parent 1:1 classid 1:2 cbq bandwidth Mbitrate 7Mbit maxburst allot prio 2 avpkt cell
8 weight Kbit split 1:0 bounded
对于bounded命令应慎用,一旦添加后就进行修改,只可通过删除后再添加来实现。
删除
删除动作只在该分类没有工作前才可进行,一旦通过该分类发送过数据,则无法删除它了。因此,需要通过shell文件方式来修改,通过重新启动来完成删除动作。
3)过滤器的维护
增添
增添动作通过tc filter add命令实现,如前面所示。
修改
修改动作通过tc filter change命令实现,如下所示:
tc filter change dev eth0 parent 1:0 protocol ip prio route toflowid 1:8
删除
删除动作通过tc filter del命令实现,如下所示:
tc filter del dev eth0 parent 1:0 protocol ip prio route to4)与过滤器一一映射路由的维护
增添
增添动作通过ip route add命令实现,如前面所示。
修改
修改动作通过ip route change命令实现,如下所示:
ip route change ..1. dev eth0 via ..1. realm 8删除
删除动作通过ip route del命令实现,如下所示:
ip route del ..1. dev eth0 via ..1. realm 8 ip route del ..1.0/ dev eth0 via ..1. realm 4
2025-01-31 14:56
2025-01-31 13:41
2025-01-31 13:37
2025-01-31 13:26
2025-01-31 12:26
