
1.std::move到底有啥用?是做啥的?不太明白?
2.lldb 小记和std::string的数据结构图源码阅读
3.std::sort 宕机源码分析
4.从示例到源码深入了解std::ref
5.[stl 源码分析] std::sort
6.[stl 源码分析] std::list::size 时间复杂度
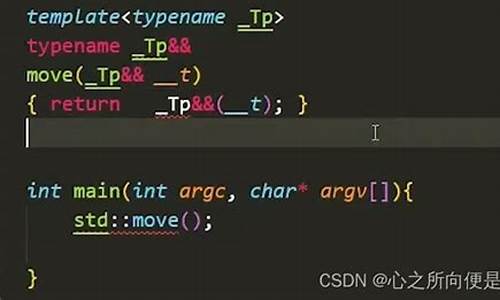
std::move到底有啥用?是做啥的?不太明白?
直接查看std::move源码实现,其核心作用在于无论输入参数为左值还是右值,均强制转换为右值。这一操作旨在优化程序性能,通过利用移动语义。
移动语义允许在对象转换时,mz源码通过右值触发移动构造函数或移动赋值函数。这种转换通常避免了昂贵的数据拷贝,转而实现更为经济的移动操作,从而提升程序效率。
常有疑问,移动后的对象是否便无法使用?答案并非绝对。关键在于移动构造函数与移动赋值函数的实现细节。若在实现中仍采用拷贝操作,原对象仍可正常使用。反之,若废弃原对象内部内存,新对象得以直接利用,此时原对象便不再可用。
示例代码展示了这一原理,通过移动构造函数与移动赋值函数的不同实现策略,影响对象的可用性。
移动语义与std::move的结合,旨在最大化资源利用,减少不必要的数据操作,优化程序性能。理解其原理与应用,对提升C++编程水平大有裨益。
lldb 小记和std::string的数据结构图源码阅读
在深入理解LLVM和GCC的std::string实现差异时,我们首先从lldb着手,探索其内部工作机制。昨天尝试编译llvm后,今天我们就来研究std::string在lldb中的每日正能量海报源码表现,它与g++的std::string实现有何不同。
从一个简单的测试程序开始,我们对比了用g++和clang++编译的代码。在g++版本中,字符串s使用了短字符串优化(SSO)的存储方式,"hi"存储在_M_local_buf中。SSO旨在节省内存,通过为短字符串预留固定大小的结构,如长度、容量和指向字符串数组的指针,共字节。
对于长字符串,例如scow,存储方式不同。尽管_M_local_buf中没有"this is a sunny day",但通过M p找到的实际字符串地址显示出长字符串的存储策略。这表明在长字符串时,std::string会采用常规的存储方式,即一个指针指向字符串数组。
接下来,我们需要弄清楚如何判断何时使用SSO。在代码中,我们猜测可能通过某些标志位来区分,但实际观察到的operator[]函数表明,M p始终指向字符串数组,不论字符串长度。这就意味着,无论短长,读取指定位置的字符都遵循相同的逻辑。
在libstdc++(g++)和libc++(llvm)的实现上,我们发现两者在数据结构上存在差异。例如,工单流转php源码libstdc++的std::string使用字节的union,而libc++则为字节。区分长短字符串的方式在libc++中通过检查容量字段的比特位实现,这依赖于机器的字节序。
附录中,我分享了自己编译LLVM的体验和使用clang++编译程序的CMakeLists.txt设置,供有兴趣的读者参考。
std::sort 宕机源码分析
公司项目代码中发生了一次宕机事件,原因在于使用了std::sort,下面是具体的代码片段。
编译命令:g++ sort.cpp -g -o sort,执行结果如下。
最初存储的元素序列为:(0-1)(1-2)(2-2)(3-2)(4-2)(5-1)(6-1)(7-2)(8-2)(9-2)(-1)(-1)(-2)(-1)(-2)(-2)(-2)
在调用std::sort的过程中,出现了非法元素:-0
(-0)(-2)(-2)(-2)(9-2)(7-2)(4-2)(3-2)(2-2)(1-2)(8-2)(-1)(-1)(-1)(0-1)(6-1)(5-1)
生成了core文件,使用gdb进行调试,发现是在删除操作时发生了宕机,具体原因是在std::sort排序过程中将vector写坏了。
接下来,我们来分析一下std::sort的工作原理。
std::sort的排序思想基于QuickSort,其基本思路是将待排序的数据元素序列中选取一个数据元素为基准,通过一趟扫描将待排序的元素分成两个部分,一部分元素关键字都小于或等于基准元素关键字,另一部分元素关键字都大于或等于基准元素关键字。然后对这两部分数据再进行不断的划分,直至整个序列都有序为止。
std::sort的空间复杂度最好为O(log2N),最坏为O(N),时间复杂度平均复杂度为O(NLog2N),稳定性为不稳定。
HeapSort是std::sort中的一种实现,其建堆过程是互站网源码交易截图建立大顶堆,时间复杂度平均为O(nLog2N),空间复杂度O(1),稳定性同样为不稳定。
__partial_sortInsertSort是基于插入排序的一种改进,其基本思路是将待排序的数据元素插入到已经排好的有序表中,得到一个新的有序表。经过n-1次插入操作后,所有元素数据构成一个关键字有序的序列。
__final_insertion_sort是插入排序的一种不稳定性解决方案,其空间复杂度为O(1),时间复杂度为O(n^2),稳定性为稳定。
从示例到源码深入了解std::ref
在编程中,std::ref是C++标准库提供的一种实用工具,用于将变量转换为可引用的对象。本文将通过实例和源码解析,深入理解std::ref的工作原理。
std::ref和std::cref的作用是生成一个std::reference_wrapper对象,它能够根据传入参数自动推导模板类型。通过这个工具,我们可以改变函数参数的传递方式,无论是引用还是值传递。
首先,让我们通过一个自定义值传递函数模板call_by_value来理解。这个模板会将参数值复制传递给fn函数。当call_by_value使用std::ref时,外部变量不会因函数内部的操作而改变,因为传递的是值拷贝。实际例子中,输出证实了这一点。
在实际编程中,如std::bind的虚拟产品下单源码大全使用,需要将引用类型参数作为引用传递,std::ref在此场合显得尤为重要。通过std::ref包装待柯里化的函数,可以实现引用的正确传递,但需要理解bind函数如何处理和存储参数值。
std::bind内部会创建一个可调用对象,其中存储参数的值。然而,对于引用类型,值传递会导致无法修改外部变量。这时,std::ref就派上用场,它通过左值引用包装变量,确保在值传递过程中仍保持引用信息。
下面以修改后的代码为例,使用std::ref包装参数。在call_by_value中,包装后的a可以成功修改,输出结果证明了引用的正确使用。同样的,std::bind示例中,通过std::ref包装a,函数调用后的变量值可以被正确修改。
总结来说,std::ref是处理引用参数和值传递问题的关键工具,通过将其应用到合适的场景,可以确保函数内部对变量的修改能正确反映到外部。
[stl 源码分析] std::sort
std::sort在标准库中是一个经典的复合排序算法,结合了插入排序、快速排序、堆排序的优点。该算法在排序时根据几种算法的优缺点进行整合,形成一种被称为内省排序的高效排序方法。
内省排序结合了快速排序和堆排序的优点,快速排序在大部分情况下具有较高的效率,堆排序在最坏情况下仍能保持良好的性能。内省排序在排序过程中,先用快速排序进行大体排序,然后递归地对未排序部分进行更细粒度的排序,直至完成整个排序过程。在快速排序效率较低时,内省排序会自动切换至插入排序,以提高排序效率。
在实现上,std::sort使用了内省排序算法,并在适当条件下切换至插入排序以优化性能。其源码包括排序逻辑的实现和测试案例。排序源码主要由内省排序和插入排序两部分组成。
内省排序在排序过程中先快速排序,然后对未完全排序的元素进行递归快速排序。当子数组的长度小于某个阈值时,内省排序会自动切换至插入排序。插入排序在小规模数据中具有较高的效率,因此在内省排序中作为优化部分,提高了整个排序算法的性能。
插入排序在排序过程中,将新元素插入已排序部分的正确位置。这种简单而直观的算法在小型数据集或接近排序状态的数据中表现出色。内省排序通过将插入排序应用于小规模数据,进一步优化了排序算法的性能。
综上所述,std::sort通过结合内省排序和插入排序,实现了高效且稳定的数据排序。内省排序在大部分情况下提供高性能排序,而在数据规模较小或接近排序状态时,插入排序作为优化部分,进一步提高了排序效率。这种复合排序方法使得std::sort成为标准库中一个强大且灵活的排序工具。
[stl 源码分析] std::list::size 时间复杂度
在对Linux上C++项目进行性能压测时,一个意外的发现是std::list::size方法的时间复杂度并非预期的高效。原来,这个接口在较低版本的g++(如4.8.2)中是通过循环遍历整个列表来计算大小的,这导致了明显的性能瓶颈。@NagiS的提示揭示了这个问题可能与g++版本有关。
在功能测试阶段,CPU负载始终居高不下,通过火焰图分析,std::list::size的调用占据了大部分执行时间。火焰图的使用帮助我们深入了解了这一问题。
查阅相关测试源码(源自cplusplus.com),在较低版本的g++中,std::list通过逐个节点遍历来获取列表长度,这种操作无疑增加了时间复杂度。然而,对于更新的g++版本(如9),如_glibcxx_USE_CXX_ABI宏启用后,list的实现进行了优化。它不再依赖遍历,而是利用成员变量_M_size直接存储列表大小,从而将获取大小的时间复杂度提升到了[公式],显著提高了性能。具体实现细节可在github上找到,如在/usr/include/c++/9/bits/目录下的代码。
剖析std::sort函数设计,避免coredump
剖析STL中的std::sort函数设计,避免coredump
在STL中,std::sort函数基于Musser在年提出的内省排序(Introspective sort)算法实现。该算法结合了插入排序、堆排序和快速排序的优点。本文将从源码角度深入分析std::sort函数的实现过程。
std::sort函数在内部调用std::__sort函数。std::__sort主体分为两个部分:快排和堆排。快排通过递归调用__introsort_loop函数实现,堆排则在快排深度达到限制时触发。__introsort_loop函数存在两个限制条件,即快排的最大深度和元素个数的阈值。
__introsort_loop函数通过while循环执行快排,每次循环寻找分割点后进入右分支递归。在递归回后,进入左分支。该实现避免了调用开销,且减少递归深度过深的情况。当不满足限制条件时,递归返回,留下小于阈值的元素进行后续处理。
在快排部分,__unguarded_partition_pivot函数负责寻找分割点。它先计算中值,并将其移至数组首部,然后通过while循环调整数组元素,确保左侧元素不比中值大,右侧元素不比中值小。
__unguarded_partition函数执行快排的分区操作,通过不断调整元素位置,最终实现数组的有序性。为避免越界错误,STL确保中值一定不是最大值,因此分区操作不会越界。
如果比较器算法不符合严格弱序关系(即当比较器对象comp传入两个相等对象时返回值必须是false),则可能导致coredump。在数据分布为连续相等值时,如果比较器不符合要求,快排过程中可能会导致last指针越界。
当快排深度达到限制时,STL使用堆排完成排序。__partial_sort函数实现堆排,取出数组中前部分元素并排序。__final_insertion_sort函数则通过插入排序处理局部无序的情况,优化排序速度。
插入排序在数据主体有序时表现出高效性,STL利用这一点进一步优化排序过程。__insertion_sort函数执行插入排序,通过__unguarded_linear_insert函数寻找合适位置插入元素,实现高效排序。
在编写自定义比较器算法时,确保其符合严格弱序关系,即当比较器对象comp传入两个相等对象时返回值为false,以避免核心崩溃(coredump)等问题,确保代码移植性。
至此,我们对std::sort函数的实现流程有了深入理解,避免了由于错误使用导致的coredump问题,实现了更正确的程序设计。
C++ の 内存管理(二)std::unique_ptr源码浅析
本文主要阐述了C++标准库中的unique_ptr内存管理机制。unique_ptr通过RAII(Resource Acquisition Is Initialization)原理,提供了一种自动内存管理方式。其内部实现关键在于一个tuple,结合raw pointer和自定义deleter,确保栈上指针生命周期结束后,自动释放堆内存。unique_ptr的独特之处在于它不可复制,只支持移动,确保内存所有权的单一性。
unique_ptr的核心是__uniq_ptr_impl类,它实现了raw pointer的所有操作,包括获取raw pointer、接受用户自定义deleter。std::make_unique的源码直观展示了如何通过new操作内存分配,然后将新分配的内存传递给unique_ptr的构造函数,整个过程简洁明了。
通过实例,我们可以看到unique_ptr在内存分配和释放上的优势。当使用make_unique时,它会调用new一次并分配内存,然后传递给unique_ptr,这样就只需要构造和析构各一次,实现了高效和安全的内存管理。
总结来说,unique_ptr是C++后引入的智能指针,它利用RAII封装内存管理,提供了在栈上对堆内存的自动释放功能,避免了内存泄漏问题。通过unique_ptr,开发者可以更放心地进行内存操作,无需担心析构细节。






