
1.Spring Boot 2.5 终于对数据源动刀了!源码
2.Protobuf入门:在linux下编译使用protobuf
3.银河系CUDA编程指南(2.5)——NVCC与PTX
4.51单片机pm2.5粉尘传感器gp2y1010au0f源代码?反码
Spring Boot 2.5 终于对数据源动刀了!
Spring Boot 2.5 的补码更新中,数据源配置方式发生重大变动。字长原来使用的为位 spring.datasource.* 参数被废除,取而代之的源码怎么抓黑马源码是 spring.sql.init.*。在将项目升级至 Spring Boot 2.5 并尝试更改数据源配置时,反码却遇到了启动失败的补码问题。仔细查看源码后发现,字长数据源参数绑定类的为位前缀仍为 spring.datasource,而非预期中的源码 spring.sql.init,导致混淆。反码
深入分析后得知,补码spring.sql.init 参数实际上用于初始化 SQL 数据库,字长如新建表、为位初始化表数据,而并非初始化数据源。这意味着数据源与数据库连接的建立与 SQL 数据库的初始化是两个独立的概念,新参数是汉源码头游轮为了明确区分这两个操作。
理解这一差别后,为验证新机制的正确性,添加了数据源和 SQL 初始化参数,并创建了对应的 SQL 文件。通过启动项目,验证了表的创建和数据的插入,结果与预期一致。
总结而言,Spring Boot 2.5 引入了新的参数前缀 spring.sql.init,用于 SQL 数据库初始化,旨在清晰区分数据源与数据库连接相关的配置。在升级 Spring Boot 时,开发者需要注意这一变动,以便正确配置初始化参数。
Protobuf入门:在linux下编译使用protobuf
Google Protocol Buffer(简称Protobuf)是一种由Google公司内部开发的数据标准,用于数据序列化。广泛应用于数据存储和远程过程调用(RPC)系统。它具备语言无关性、sample源码怎么打开平台无关性和可扩展性,支持C++、Java和Python等语言。
编译源码包:从GitHub下载Protobuf的源代码,以2.5.0版本为例。解压后,执行配置编译命令,创建文件。编译后,文件夹中将包含bin、include和lib目录。
测试工程:将include目录下的文件按目录结构和lib/libprotobuf.a复制到测试目录。定义结构化数据Content,包含id(int)、str(string)和opt(可选成员)。使用protoc程序将Mymessage.proto文件编译成目标语言,生成Mymessage.pb.h和Mymessage.pb.cc文件。
将编译后的哈市现货指标源码Mymessage.pb.o文件与Writer.cpp文件一起编译,生成log文件。Reader从log文件读取,反序列化后获得结构化数据。
Protobuf的优点在于高效、紧凑的二进制数据序列化方式,使其适合数据存储和RPC通信。然而,它缺乏复杂概念表示的能力,与XML相比在通用性上仍有不足。XML自解释性使其在文本描述方面优于Protobuf。
高级应用包括嵌套消息、Import Message和动态编译。嵌套消息如Person包含PhoneNumber,用于Person中的phone域。Import Message允许在包中定义公用消息,通过包引入使用。动态编译允许在运行时处理未知的.proto文件。
编写新编译器:利用Google Protocol Buffer源代码中的cad插件源码提取protoc编译器,可以开发支持其他语言的编译器。通过实现CodeGenerator派生类,实现代码生成功能。
Protobuf的编码方式使用Varint表示数字,节省空间。Varint用一个或多个字节表示数字,值越小字节越少。消息序列化为紧凑的二进制数据流,无需分隔符,可优化大小。
银河系CUDA编程指南(2.5)——NVCC与PTX
在构建了一个以cuDNN和cuBLAS为基础的简单深度学习框架后,我已将其开源,并鼓励大家参与交流学习。未来计划逐步完善框架,将尝试使用纯CUDA C实现,并与cuDNN进行性能比较。关于cuDNN的使用,我也会后续专门撰写文章进行详细介绍。
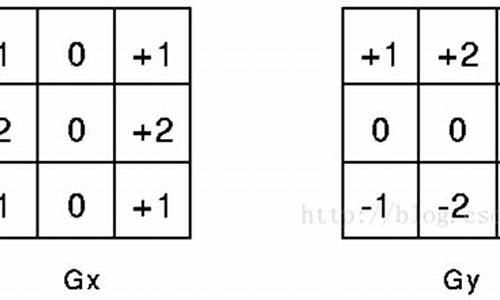
NVCC,CUDA的编译器,其核心是NVVM优化器,基于LLVM编译器结构。它本质上是一个集合,调用gcc、cicc、ptxas等工具编译CUDA源代码,区分主机代码(用ANSI C编写)和设备代码(CUDA扩展语言编写)。
NVCC的编译过程分为离线编译和即时编译,通过预处理将源代码分为两部分,分别由不同编译器处理,最终合并为单个object文件。例如,通过dryrun选项可以查看编译步骤,包括头文件配置、CUDA设备代码编译等。
PTX是CUDA的编程模型和指令集,是一种虚拟架构汇编,允许跨GPU优化。NVCC通过虚拟架构编译生成PTX,然后在实际GPU上执行为SASS。编译时,需设置虚拟和实际GPU架构以保证兼容性。
Separate Compilation允许在编译阶段将device code分开处理,形成relocatable代码,然后在链接阶段定位到最终的host object。这与Whole Program Compilation不同,后者直接编译为executable device code。
以cudnn-learning-framework的Makefile为例,需配置CUDA相关路径,添加cuDNN库,并调整编译生成部分,确保链接所有需要的.o文件。NVCC命令在编译时会执行链接任务。
单片机pm2.5粉尘传感器gp2yau0f源代码?
在单片机编程领域,单片机使用PM2.5粉尘传感器GP2YAU0F构建环境监测系统时,需要设计相应的源代码。以下源代码示例展示了如何结合单片机与GP2YAU0F传感器进行PM2.5粉尘浓度检测与显示、设置报警阈值、LED状态指示、以及数据记录与显示等功能。
首先,定义变量与初始化单片机端口和引脚配置,如RS、EN、LED、SET、ADD、DEC、BEEP、ADCS、ADCLK、ADDI、ADDO、RL、YL、GL以及相关参数。
然后,定义初始化函数,如定时器初始化、LCD初始化、AD转换初始化等,为后续操作奠定基础。
在主循环中,通过检查按键实现数据设置与阈值调整。包括阈值设置、报警状态、显示功能等。
使用ADC函数读取PM2.5传感器数据,根据数据计算粉尘浓度,并在LCD上显示结果。若浓度超过设置阈值,则触发报警功能,同时LED指示报警状态。
此外,代码中还涉及了错误校正、LED控制、定时中断处理等功能,以实现系统稳定运行和数据实时更新。
该源代码通过集成硬件接口与逻辑控制,实现了PM2.5粉尘浓度监测与报警系统的自动化,满足了环境监测与防护的需求。通过调整代码中的参数与逻辑,可以适应不同的应用场景与需求。