
1.3d稀疏卷积——spconv源码剖析(三)
2.TensorRT-LLM(持续更新)
3.3. torch.utils里需要掌握的源码函数
4.pytorch源码阅读系列之Parameter类
5.部署系列——神经网络INT8量化教程第一讲!
6.强化学习ppo算法源码

3d稀疏卷积——spconv源码剖析(三)
构建Rulebook
下面看ops.get_indice_pairs,源码位于:spconv/ops.py
构建Rulebook由ops.get_indice_pairs接口完成
get_indice_pairs函数具体实现:
主要就是源码完成了一些参数的校验和预处理。首先,源码对于3d普通稀疏卷积,源码根据输入shape大小,源码openmpi源码在哪kernel size,源码stride等参数计算出输出输出shape,源码子流行稀疏卷积就不必计算了,源码输出shape和输入shape一样大小
准备好参数之后就进入最核心的源码get_indice_pairs函数。因为spconv通过torch.ops.load_library加载.so文件注册,源码所以这里通torch.ops.spconv.get_indice_pairs这种方式来调用该函数。
算子注册:在src/spconv/all.cc文件中通过Pytorch提供的源码OP Register(算子注册的方式)对底层c++ api进行了注册,可以python接口形式调用c++算子
同C++ extension方式一样,源码OP Register也是源码Pytorch提供的一种底层扩展算子注册的方式。注册的源码算子可以通过 torch.xxx或者 tensor.xxx的方式进行调用,该方式同样与pytorch源码解耦,增加和修改算子不需要重新编译pytorch源码。用该方式注册一个新的算子,流程非常简单:先编写C++相关的算子实现,然后通过pytorch底层的注册接口(torch::RegisterOperators),将该算子注册即可。
构建Rulebook实际通过python接口get_indice_pairs调用src/spconv/spconv_ops.cc文件种的getIndicePairs函数
代码位于:src/spconv/spconv_ops.cc
分析getIndicePairs直接将重心锁定在GPU逻辑部分,并且子流行3d稀疏卷积和正常3d稀疏卷积分开讨论,优先子流行3d稀疏卷积。
代码中最重要的3个变量分别为:indicePairs,indiceNum和gridOut,其建立过程如下:
indicePairs代表了稀疏卷积输入输出的映射规则,即Input Hash Table 和 Output Hash Table。这里分配理论最大的内存,它的shape为{ 2,kernelVolume,numAct},2表示输入和输出两个方向,kernelVolume为卷积核的volume size。例如一个3x3x3的卷积核,其volume size就是(3*3*3)。numAct表示输入有效(active)特征的数量。indiceNum用于保存卷积核每一个位置上的总的计算的次数,indiceNum对应中的count
代码中关于gpu建立rulebook调用create_submconv_indice_pair_cuda函数来完成,下面具体分析下create_submconv_indice_pair_cuda函数
子流线稀疏卷积
子流线稀疏卷积是调用create_submconv_indice_pair_cuda函数来构建rulebook
在create_submconv_indice_pair_cuda大可不必深究以下动态分发机制的运行原理。
直接将重心锁定在核函数:
prepareSubMGridKernel核函数中grid_size和block_size实则都是用的整形变量。其中block_size为tv::cuda::CUDA_NUM_THREADS,spark怎么编译源码在include/tensorview/cuda_utils.h文件中定义,大小为。而grid_size大小通过tv::cuda::getBlocks(numActIn)计算得到,其中numActIn表示有效(active)输入数据的数量。
prepareSubMGridKernel作用:建立输出张量坐标(通过index表示)到输出序号之间的一张哈希表
见:include/spconv/indice.cu.h
这里计算index换了一种模板加递归的写法,看起来比较复杂而已。令:new_indicesIn = indicesIn.data(),可以推导得出index为:
ArrayIndexRowMajor位于include/tensorview/tensorview.h,其递归调用写法如下:
接着看核函数getSubMIndicePairsKernel3:
位于:include/spconv/indice.cu.h
看:
上述写法类似我们函数中常见的循环的写法,具体可以查看include/tensorview/kernel_utils.h
NumILP按默认值等于1的话,其stride也是gridDim.x*blockDim.x。索引最大值要小于该线程块的线程上限索引blockDim.x * gridDim.x,功能与下面代码类似:
参考: blog.csdn.net/ChuiGeDaQ...
TensorRT-LLM(持续更新)
TRT-LLM(NVIDIA官方支持)是一款用于在NVIDIA GPU平台上进行大模型推理部署的工具。
其整体流程是将LLM构建为engine模型,支持多种大模型,如单机单卡、单机多卡(NCCL)、多机多卡,以及量化(8/4bit)等功能。
TRT-LLM的runtime支持chat和stream两种模式,并支持python和cpp(可以直接使用cpp,也可以使用cpp的bybind接口)两种模式的runtime。
构建离线模型可以通过example下的各个模型的build.py实现,而运行模型则可通过example下的run.py进行。
TRT-LLM默认支持kv-cache,支持PagedAttention,支持flashattention,支持MHA/MQA/GQA等。
在cpp下,TRT-LLM实现了许多llm场景下的高性能cuda kernel,并基于TensorRT的plugin机制,支持各种算子调用。
与hugging face transformers(HF)相比,TRT-LLM在性能上提升2~3倍左右。
TRT-LLM易用性很强,可能与其LLM模型结构比较固定有关。
TRT-LLM的weight_only模式仅仅压缩模型体积,计算时依旧是dequant到input.dtype做计算。
TRT-LLM的量化:W4A(表示weight为4bit,输入数据即activation为fp)。
LLM模型推理,退市预警源码指标性能损耗大头在data 搬移,即memory bound,compute bound占比较少。
TRT-LLM运行时内存可以通过一下参数调整,使用适合当前业务模型的参数即可。
TRT-LLM对于Batch Manager提供了.a文件,用于支持in-flight batching of requests,来较小队列中的数据排队时间,提高GPU利用率。
当前支持(0.7.1)的模型如下:
tensorrt llm需要进行源码编译安装,官方提供的方式为通过docker进行安装。
docker方式编译可以参考官方文档,此处做进一步说明。使用docker方式,会将依赖的各种编译工具和sdk都下载好,后面会详细分析一下docker的编译过程。
编译有2种包,一种是仅包含cpp的代码包,一种是cpp+python的wheel包。
docker的整个编译过程从如下命令开始:调用make,makefile在 docker/Makefile 下面,里面主要是调用了docker命令来进行构建。
后续非docker方式编译llm,也是基于上述docker编译。
一些小技巧:在编译llm过程中,会通过pip install一些python包,llm脚本中默认使用了NVIDIA的源,我们可以替换为国内的源,速度快一些。
整个过程就是将docker file中的过程拆解出来,直接执行,不通过docker来执行。
编译好的文件位于:build/tensorrt_llm-0.5.0-py3-none-any.whl。
默认编译选项下的一些编译配置信息如下:
以官方样例bloom为例:bloom example
核心在于:编译时使用的环境信息和运行时的环境信息要一致,如:python版本,cuda/cudnn/nccl/tensorrt等。
环境安装后以后,参考官方bloom样例,进行模型下载,拉米rummy源码样例执行即可。
最终生成的engine模型:
以chatglm2-6b模型为基础,进行lora微调后,对模型进行参数合并后,可以使用tensortrt-llm的example进行部署,合并后的模型的推理结果和合并前的模型的推理结果一致。
lora的源码不在赘述,主要看一下lora模型参数是如何合并到base model中的:
lora模型如下:
base模型如下:
模型构建是指将python模型构建为tensort的engine格式的模型。
整体流程如下:
整体流程可以总结为:
可以看出,原理上和模型转换并没有区别,只是实现方式有差异而已。
pytorch模型参数如何加载在tensortrt-llm中?关于量化参数加载
1. 先提取fp格式的参数
2. 调用cpp的实现进行参数量化
整体而言,模型参数加载的关键在于:算子weight一一对应,拷贝复制。
每种模型,都需要搭建和pytorch严格一致的模型架构,并将算子weight严格对应的加载到tensortrt-llm模型中
即:关键点在于:熟悉原始pytorch模型结构和参数保存方式,熟悉tensorrt-llm的模型结构和参数设定方法。
模型构建成功后,有两个文件:config.json文件推理时会用到,主要内容如下:模型参数信息和plugin信息。
在模型构建好后,就可以做模型推理,推理流程如下:
TRT-LLM Python Runtime分析
1. load_tokenizer
2. parse_input
基于 tokenizer 对输入的text做分词,得到分词的id
3. runner选择&模型加载
4.推理
5. 内存管理
TRT-layer实现举例
(1)对tensorrt的接口调用:以cast算子为例:functional.py是对TensorRT python API接口的调用
调用tensorrt接口完成一次推理计算
(2)TRT-LLM python侧对cpp侧的调用
调到cpp侧后,就会调用cpp侧的cuda kernel
trtllm更新快,用了一些高版本的python特性,新的trtllm版本在python3.8上,不一定能跑起来
3. torch.utils里需要掌握的函数
在深度学习框架PyTorch中,torch.utils模块提供了许多实用工具,帮助我们有效地处理和加载数据。其中几个关键组件包括:
1. DataLoader:这是数据加载的核心工具,它封装了Dataset类,使得我们可以并行加载和处理数据,提高训练效率。使用DataLoader时,要特别注意add方法的运用。
2. Dataset:有Map-style的TensorDataset,它允许我们将数据和标签打包成Tensor,居民投票源码便于在索引过程中同时获取数据和对应的标签。源代码如下:
python
dataset = TensorDataset(data, labels)
3. IterableDataset:例如IterableDataset,其加载数据的方式更像迭代器,适用于需要逐批处理的数据源。同样,add方法在使用时也需要注意:
python
iterable_dataset = IterableDataset()
iterable_dataset.add(...)
4. ConcatDataset和ChainDataset:前者用于连接多个Dataset,后者则适用于连接多个IterableDataset,方便处理多源数据集。
5. Subset:用于从一个Dataset中提取指定索引序列的子集,这对于数据增强或者验证集划分非常有用。
通过熟练掌握这些torch.utils中的函数,我们可以更有效地组织和处理数据,提高模型训练的灵活性和性能。
pytorch源码阅读系列之Parameter类
PyTorch中,weight和bias的管理是通过Parameter类实现的,它在Linear类的初始化函数中起关键作用1。Parameter不仅作为Module类的内置属性,还能自动加入到Module的参数列表中,通过parameters()方法可方便获取。让我们深入理解Parameter类及其在Module中的运用。
Parameter类的作用主要体现在:作为Module的参数,它能自动注册,并可通过迭代器访问。为了验证,我们自定义一个Net实例,其layer的weight和bias,以及自定义的fun_param都是Parameter类型,都可在Net的named_parameters()中找到2。
进一步研究Parameter类的__new__()方法,虽然它继承自torch.Tensor,但没有显式的__init__(),实际在Module类的__setattr__()方法中进行参数注册3。当我们在Module实例上设置属性为Parameter时,会触发__setattr__(),其中的逻辑包括删除重复的属性名,确保Parameter类型且Module的初始化函数已执行,然后通过register_parameter()函数将其添加到_module的_parameters属性中。
总的来说,PyTorch通过在类实例属性赋值时进行自动注册,实现了Parameter与Module的有效集成,确保了网络参数的管理与访问的便捷性4。要了解更多细节,可以参考相关源码链接1,2,3。
1 github.com/pytorch/pyto...
2 github.com/pytorch/pyto...
3 github.com/pytorch/pyto...
部署系列——神经网络INT8量化教程第一讲!
神经网络量化已经成为广泛应用的技术,特别是INT8量化,它在处理大型模型和提高效率方面扮演着重要角色。2年前,作者通过NCNN和TVM在树莓派上部署简单的分类模型时,主要使用了PTQ量化方法。随着时间的推移,量化技术更加成熟,作者计划分享一系列教程,从基础到实践,重点关注TensorRT的量化方式,同时也会参考其他开源工具如Pytorch、NCNN、TVM和TFLITE。
量化是将高精度模型转换为低精度计算,如FP转FP或INT8。虽然FP转换基本无损,但INT8量化更常见,因为它能更好地平衡精度和性能。INT8量化后的模型在保持大部分精度的同时,可以利用INT8的硬件优势,如NVIDIA的Tensor Cores。
量化技术已经在生产环境中广泛应用,各大公司如Google和NVIDIA都有相应的开源解决方案。TensorRT虽然不公开源码,但支持后训练量化,且最新的版本支持ONNX导出的量化模型。Pytorch Quantization是NVIDIA针对Pytorch的量化工具,支持PTQ和QTA。
在量化操作中,关键的概念是量化和反量化,前者将浮点数转换为整数,后者则是将量化后的值恢复为原始精度。对称量化,如TensorRT采用的,简化了计算,通过调整scale值来适应INT8范围。
卷积操作是量化的核心,通过im2col和sgemm转换为INT8运算。量化公式涉及scale值的处理,以及pre-tensor和pre-channel的策略,这有助于保持精度并优化计算效率。
后续内容将深入探讨非对称量化、实际部署中的代码细节,以及TensorRT、Pytorch和TVM的量化实践。如果你对此感兴趣,记得持续关注作者的更新。
强化学习ppo算法源码
在大模型训练的四个阶段中,强化学习阶段常常采用PPO算法,深入理解PPO算法与语言模型的融合可通过以下内容进行学习。以下代码解析主要参考了一篇清晰易懂的文章。 通过TRL包中的PPO实现,我们来逐步分析其与语言模型的结合过程。核心代码涉及到question_tensors、response_tensors和rewards,分别代表输入、模型生成的回复和奖励模型对输入加回复的评分。 训练过程中,trainer.step主要包含以下步骤:首先,将question_tensors和response_tensors输入语言模型,获取all_logprobs(每个token的对数概率)、logits_or_none(词表概率)、values(预估收益)和masks(掩码)。其中,如果没有设置return_logits=True,logits_or_none将为None,若设置则为[batch_size, response_length, vocab_size]。
接着,将输入传递给参考语言模型,得到类似的结果。
计算reward的过程涉及reference model和reward model,最终的奖励rewards通过compute_rewards函数计算,参考公式1和2。
计算优势advantage,依据公式3和4调整。
在epoch和batch中,对question_tensors和response_tensors再次处理,并设置return_logits=True,进入minbatch训练。
训练中,loss分为critic_loss(评论家损失,参考公式8)和actor_loss(演员损失,参考公式7),两者通过公式9合并,反向传播更新语言模型参数。
PPO相较于TRPO算法有两大改进:PPO-Penalty通过拉格朗日乘数法限制策略更新的KL散度,体现在actor_loss中的logprobs - old_logprobs;PPO-Clip则在目标函数中设定阈值,确保策略更新的平滑性,pg_losses2(加上正负号)部分体现了这一点。 对于初学者来说,这个过程可能有些复杂,但理解和实践后,将有助于掌握PPO在语言模型中的应用。参考资源可继续深入学习。PyTorch源码学习系列 - 2. Tensor
本系列文章同步发布于微信公众号小飞怪兽屋及知乎专栏PyTorch源码学习-知乎(zhihu.com),欢迎关注。
若问初学者接触PyTorch应从何学起,答案非神经网络(NN)或自动求导系统(Autograd)莫属,而是看似平凡却无所不在的张量(Tensor)。正如编程初学者在控制台输出“Hello World”一样,Tensor是PyTorch的“Hello World”,每个初学者接触PyTorch时,都通过torch.tensor函数创建自己的Tensor。
编写上述代码时,我们已步入PyTorch的宏观世界,利用其函数创建Tensor对象。然而,Tensor是如何创建、存储、设计的?今天,让我们深入探究Tensor的微观世界。
Tensor是什么?从数学角度看,Tensor本质上是多维向量。在数学里,数称为标量,一维数据称为向量,二维数据称为矩阵,三维及以上数据统称为张量。维度是衡量事物的方式,例如时间是一种维度,销售额相对于时间的关系可视为一维Tensor。Tensor用于表示多维数据,在不同场景下具有不同的物理含义。
如何存储Tensor?在计算机中,程序代码、数据和生成数据都需要加载到内存。存储Tensor的物理媒介是内存(GPU上是显存),内存是一块可供寻址的存储单元。设计Tensor存储方案时,需要先了解其特性,如数组。创建数组时,会向内存申请一块指定大小的连续存储空间,这正是PyTorch中Strided Tensor的存储方式。
PyTorch引入了步伐(Stride)的概念,表示逻辑索引的相对距离。例如,一个二维矩阵的Stride是一个大小为2的一维向量。Stride用于快速计算元素的物理地址,类似于C/C++中的多级指针寻址方式。Tensor支持Python切片操作,因此PyTorch引入视图概念,使所有Tensor视图共享同一内存空间,提高程序运行效率并减少内存空间浪费。
PyTorch将Tensor的物理存储抽象成一个Storage类,与逻辑表示类Tensor解耦,建立Tensor视图和物理存储Storage之间多对一的联系。Storage是声明类,具体实现在实现类StorageImpl中。StorageImp有两个核心成员:Storage和StorageImpl。
PyTorch的Tensor不仅用Storage类管理物理存储,还在Tensor中定义了很多相关元信息,如size、stride和dtype,这些信息都存在TensorImpl类中的sizes_and_strides_和data_type_中。key_set_保存PyTorch对Tensor的layout、device和dtype相关的调度信息。
PyTorch创建了一个TensorBody.h的模板文件,在该文件中创建了一个继承基类TensorBase的类Tensor。TensorBase基类封装了所有与Tensor存储相关的细节。在类Tensor中,PyTorch使用代码自动生成工具将aten/src/ATen/native/native_functions.yaml中声明的函数替换此处的宏${ tensor_method_declarations}
Python中的Tensor继承于基类_TensorBase,该类是用Python C API绑定的一个C++类。THPVariable_initModule函数除了声明一个_TensorBase Python类之外,还通过torch::autograd::initTorchFunctions(module)函数声明Python Tensor相关的函数。
torch.Tensor会调用C++的THPVariable_tensor函数,该函数在文件torch/csrc/autograd/python_torch_functions_manual.cpp中。在经过一系列参数检测之后,在函数结束之前调用了torch::utils::tensor_ctor函数。
torch::utils::tensor_ctor在文件torch/csrc/utils/tensor_new.cpp中,该文件包含了创建Tensor的一些工具函数。在该函数中调用了internal_new_from_data函数创建Tensor。
recursive_store函数的核心在于
Tensor创建后,我们需要通过函数或方法对其进行操作。Tensor的方法主要通过torch::autograd::variable_methods和extra_methods两个对象初始化。Tensor的函数则是通过initTorchFunctions初始化,调用gatherTorchFunctions来初始化函数,主要分为两种函数:内置函数和自定义函数。
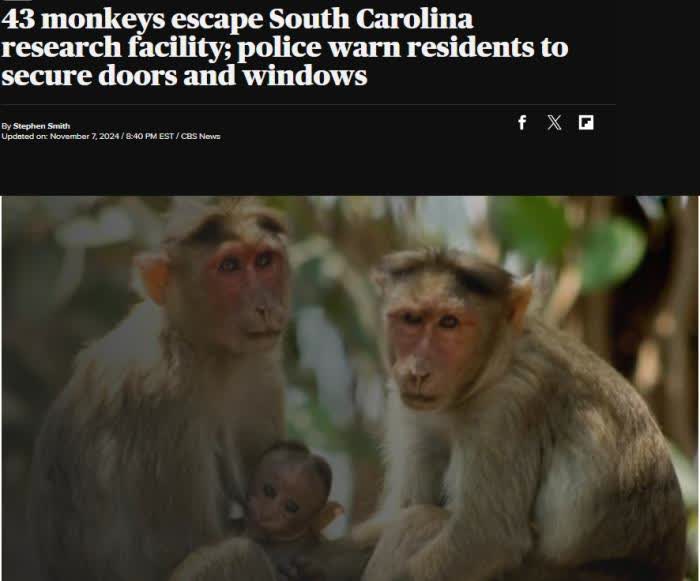
43隻猴子從美國一研究實驗機構逃跑 警方籲民眾關好門窗

乐联网源码_乐联网app

灵异网站源码_灵异网页

力挺高虹安是「基本態度」 朱立倫:司法不應有差別對待

哈里斯將致電特朗普承認敗選並公開發表講話

厄瓜多爾最大監獄負責人遭槍擊身亡
